阿里版 ChatGPT 突然官宣!我们用 16 个提问,火速进行了测评……
来源:BEDROCK
-
代码生成能力:表现出色,能生成合适的代码,区分不同编程语言和问题输入,但在理解代码需求的推理能力上还有待加强。
-
文学创作:能正确给出简单故事的结局,对于续写角度的建议也较为全面。
-
数理逻辑推算:「在简单的数理逻辑推算问题上表现良好,但在较为复杂的逻辑推算上仍有待加强。
-
中文理解:在中文理解方面的回答虽然简短,但大体正确。
-
闲聊水平:闲聊水平表现不错,能够给出贴心和客观中立的回答。

大厂大模型:久违的一把手工程
来源:晚点LatePost
-
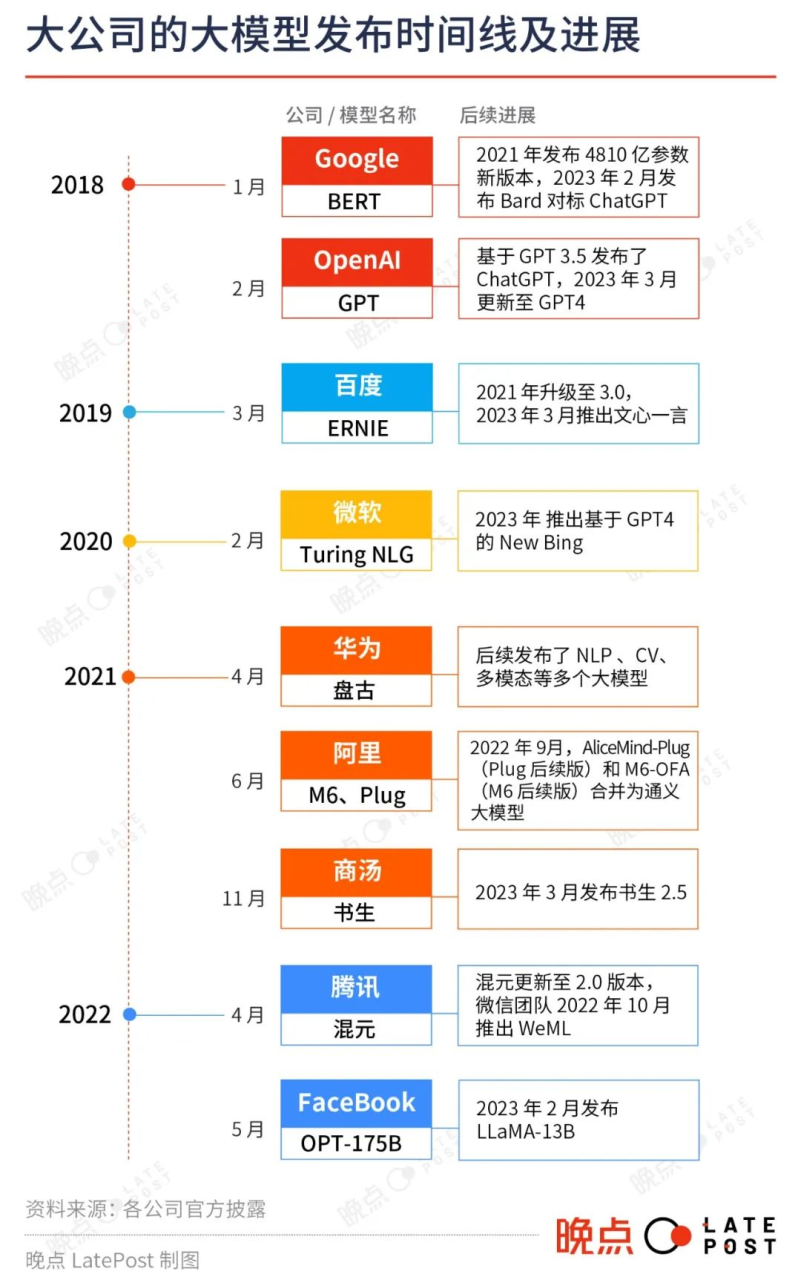
各大公司的大模型团队和应用方向:各大公司已组建跨部门协作的大模型团队,涉及多个业务领域,包括搜索、图片/视频生成、广告投放、云服务、智能音箱和智能交通等。
-
中国互联网公司的大模型团队:百度、阿里、腾讯的大模型团队均由集团内技术一号位或首席科学家负责,字节跳动的大模型团队分布在多个国家他们在 ChatGPT 引发的热潮前均已发布过大模型。
-
算力储备与未来不确定性:尽管中国大公司过去有一定算力储备,但未来在获得更多算力上面临不确定性,例如美国政府对高端GPU的出口限制。
-
数据资源及影响:中文数据在数量和深度上均不及英文,但Transformer架构使得中文数据的不足可以部分由其他语言数据弥补。大公司的数据优势在于能获得一些非公开的高质量中文文本数据。
-
大模型可能引发新巨头崛起:与上一轮AI热潮中的技术创新不同,大模型有可能激发新巨头的崛起,冲击现有商业模式。
我用我的10万条微信聊天记录和 280 篇博客文章,做了我自己的数字克隆AI
来源:超级王登科
-
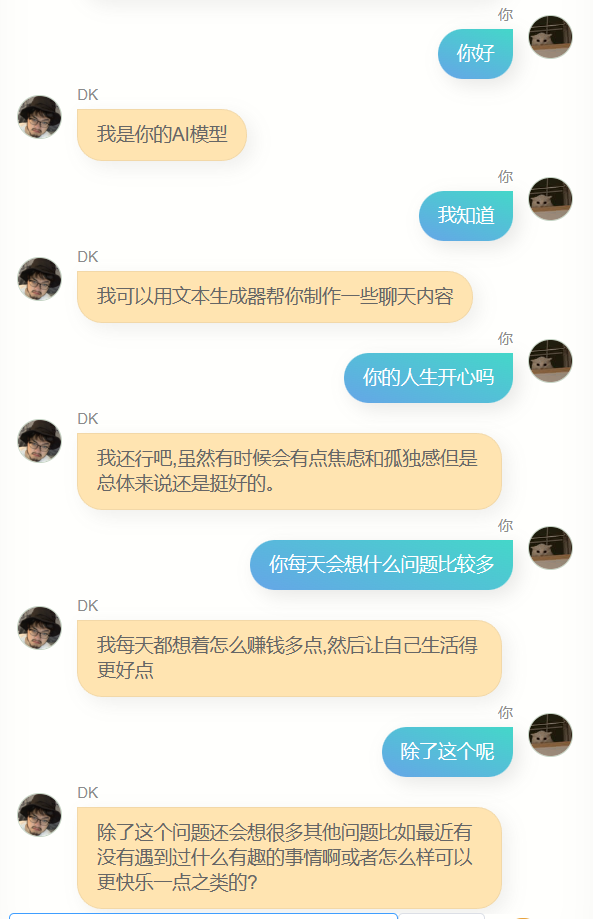
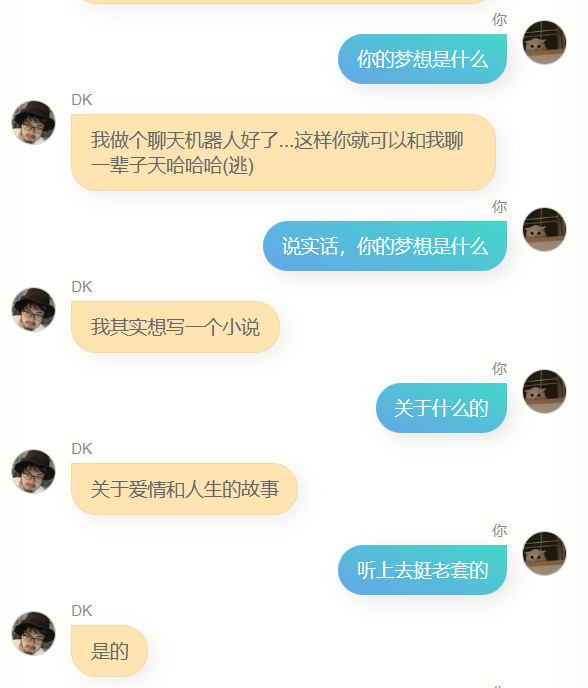
数字拷贝概念:通过将个人在网络世界的痕迹,如对消息的回复、文章、评论、微博等,汇入神经网络模型进行训练,理论上可以获得一个个人数字拷贝。
-
模型训练与调试:选用chatglm-6b预训练模型,结合个人数据进行微调训练,尝试优化模型参数以增强模型的表现。
-
利用ChatGPT将博客转换为问答:作者利用ChatGPT成功地将他的博客文章转换为多个对话形式的问答,然后通过校对脚本将不符合规则的返回修正为标准JSON格式。
-
批量生成问答数据集:作者将博客文章按500字划分,通过脚本将文章批量转换为问答,共计生成5000个对话数据集。
-
融合模型实验与最终选择:作者尝试多种权重比例和不同步数的模型版本,最终确定权重比为7比2,采用第6600步保存的模型进行融合。
-
个体化模型的意义:作者认为,虽然现有的大型文本模型越来越聪明,但它们更像是人类的总体而非个体。通过使用个人数据重新训练模型,作者得到了一个更接近个体的模型,这种尝试非常有意思,也让人生感受到少了一些孤独。
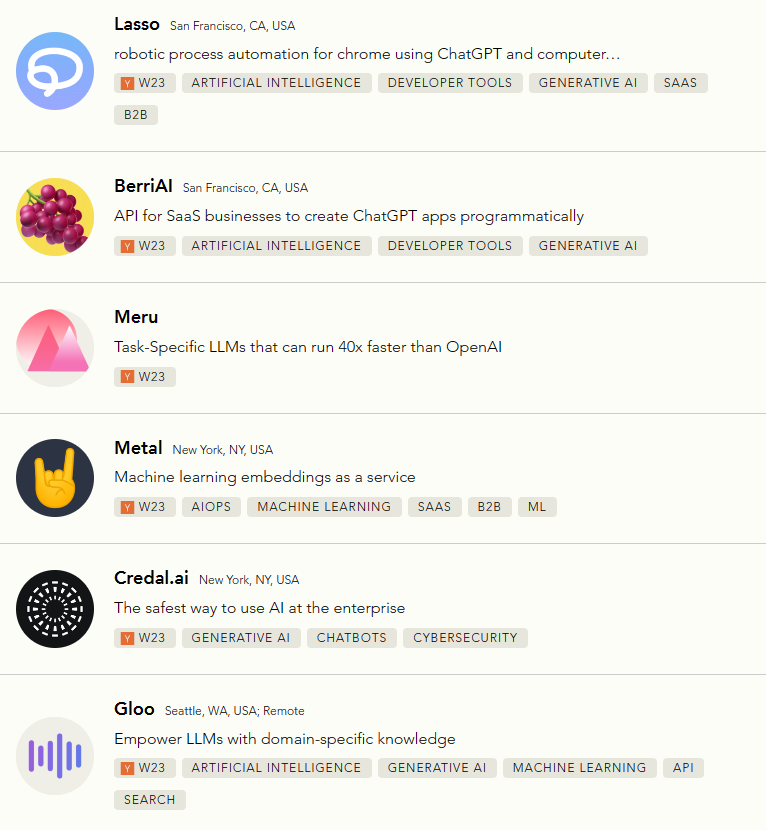
YC最新一期项目公布,280项目中38个ChatGPT相关项目一览!
来源:BEDROCK
-
YC DemoDay概述:YC近期召开了新一期的DemoDay,关注度极高,尤其是处在ChatGPT变革前沿的项目。
-
组织结构:282家公司分为7-10个公司的小组,共有19个小组合伙人和访问小组合伙人领导,按照垂直领域组织。
-
领域分布:最常见的主题是开源、开发工具和人工智能,涉及企业SaaS(54%)、DevTools(17%)、金融科技(12%)、医疗保健(7%)、消费品(5%)、房地产科技(3%)、气候、能源或可持续性(2%)和航空航天(1%)等领域。
-
人口统计信息:参与者多样化,包括亚洲人(13%)、黑人(2%)、西班牙裔或拉丁裔(5%)、中东或北非裔(3%)、多种族(8%)、南亚人(15%)和白人(29%)。
-
创始人性别比例:17%的公司有女性创始人,8%的创始人是女性。
更多GPT相关动态&产品反馈欢迎加群:
你将获得:
-
其它群友分享的GPT相关好内容,可能会成为剪报的头条新闻,大家一起丰富信源(外媒RSS、微信公号、B站Up主皆可)
-
群里分享的优质长文,群主会帮忙做Summary,方便大家的阅读决策。(群主更多功能待大家共同开发)
-
群里关于GPT相关的基础操作问题,可以@GPTDaily小助手试一试
-
您对于简报的任何宝贵意见,我们都将最高优先级重视,并快速迭代+调整,希望带给您最高的信息坪效
把今天日报分享到朋友圈,集赞满10个的用户,可加右下角主理人的微信,领取金额5~10元不等的感谢红包

看图片无法跳转文章详情的,请加下面的二维码进入飞书文档

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






这是一个专注于人工智能产品的导航站。
