Unlimiformer: Long-Range Transformers with Unlimited Length Input
解决问题: 这篇论文的目标是解决Transformer模型输入长度受限的问题,因为Transformer需要关注输入中的每个标记。作者提出了一种新的方法,称为Unlimiformer,可以包装任何预训练的编码器-解码器Transformer,并将注意力计算分配到单个k最近邻索引中,从而实现对极长输入序列的索引。
关键思路: Unlimiformer的关键思路是使用k最近邻索引来代替传统的注意力计算,从而允许对极长的输入序列进行索引。相比于当前领域的研究,这篇论文的思路具有新意,因为它可以扩展预训练模型的输入长度而不需要额外的学习权重或修改代码。
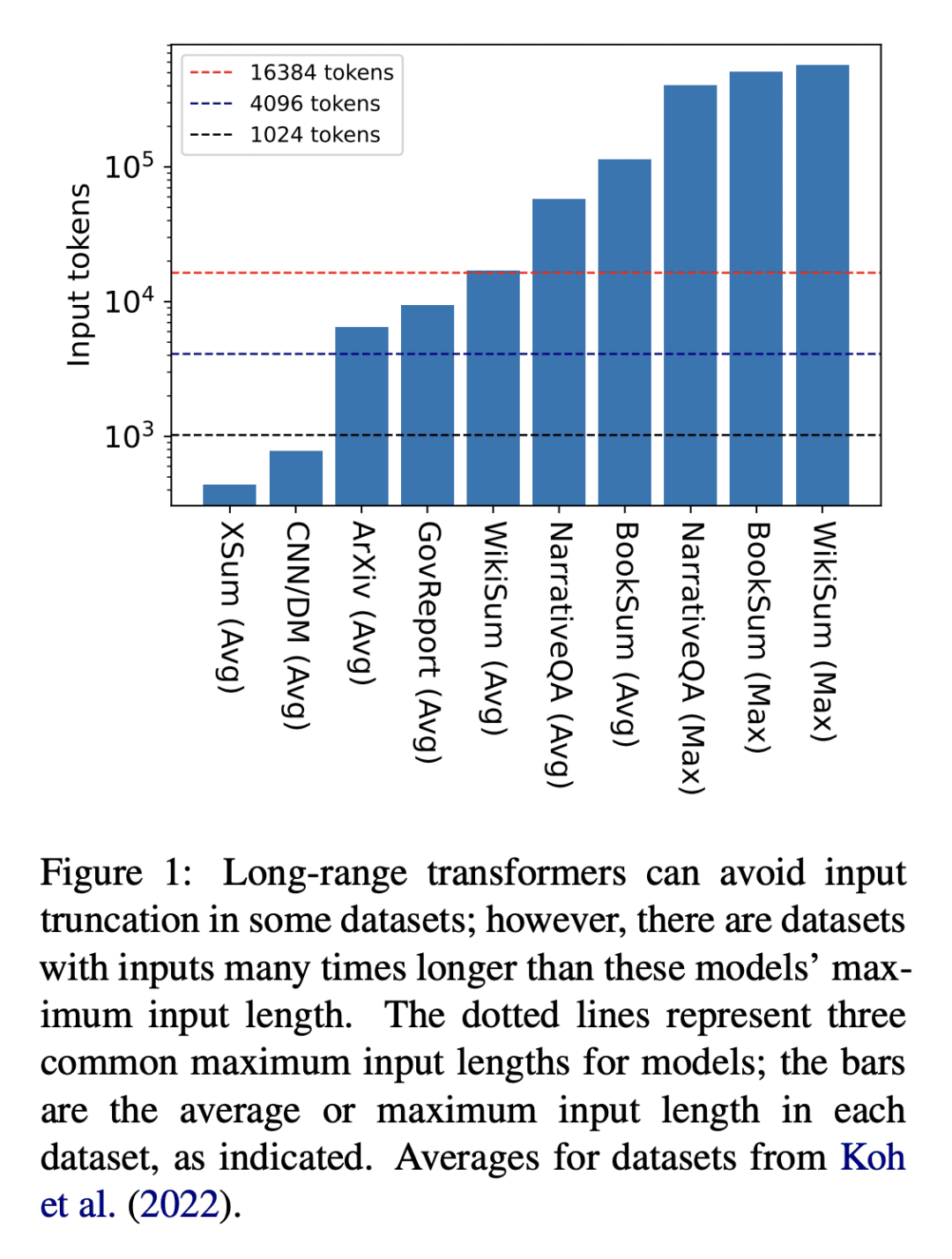
其他亮点: 论文的实验表明,Unlimiformer在多个长文档和多文档摘要基准测试中都表现出良好的效果,可以对来自BookSum数据集的长达350k标记的输入进行摘要,而不需要在测试时截断输入。Unlimiformer还可以扩展预训练模型(如BART和Longformer)的输入长度,而不需要额外的学习权重或修改代码。此外,作者已经将他们的代码和模型公开发布在GitHub上,供其他研究人员使用和参考。
关于作者: Amanda Bertsch、Uri Alon、Graham Neubig和Matthew R. Gormley是本文的主要作者。他们分别来自卡内基梅隆大学、魏茨曼科学研究所和卡内基梅隆大学。Graham Neubig在自然语言处理领域有很多代表作,包括“Neural Machine Translation by Jointly Learning to Align and Translate”和“Learning to Translate in Real-time with Neural Machine Translation”。
相关研究: 最近有一些相关的研究,例如“Longformer: The Long-Document Transformer”(Iz Beltagy、Matthew E. Peters和Arman Cohan)和“Big Bird: Transformers for Longer Sequences”(Manzil Zaheer等人)。这些研究都尝试解决Transformer模型输入长度受限的问题,但使用的方法不同。
论文摘要:本文提出了 Unlimiformer 方法,可以包装任何现有的预训练编码器-解码器 transformer 模型,并将所有层的注意力计算转移到一个 $k$ 最近邻索引中,从而可以索引非常长的输入序列,而每个解码器层中的每个注意力头都检索其前 $k$ 个键,而不是关注每个键。在几个长文档和多文档摘要基准测试中,我们展示了 Unlimiformer 的有效性,表明它可以摘要来自 BookSum 数据集的长达 350k 个标记的输入,而无需在测试时截断输入。Unlimiformer 扩展了预训练模型(如 BART 和 Longformer),使它们可以处理无限输入,而不需要额外的学习权重和不需要修改它们的代码。我们在 https://github.com/abertsch72/unlimiformer 上公开了我们的代码和模型。
相关文章
