AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
https://arxiv.org/pdf/2304.12995.pdf
https://github.com/AIGC-Audio/AudioGPT
提出AudioGPT,一种多模态AI系统,将ChatGPT与音频基础模型相结合,以处理复杂的音频信息和支持口头对话,在多轮对话中展现出强大的音频理解和生成能力,使用户可以轻松地创建丰富多样的音频内容。
解决问题:
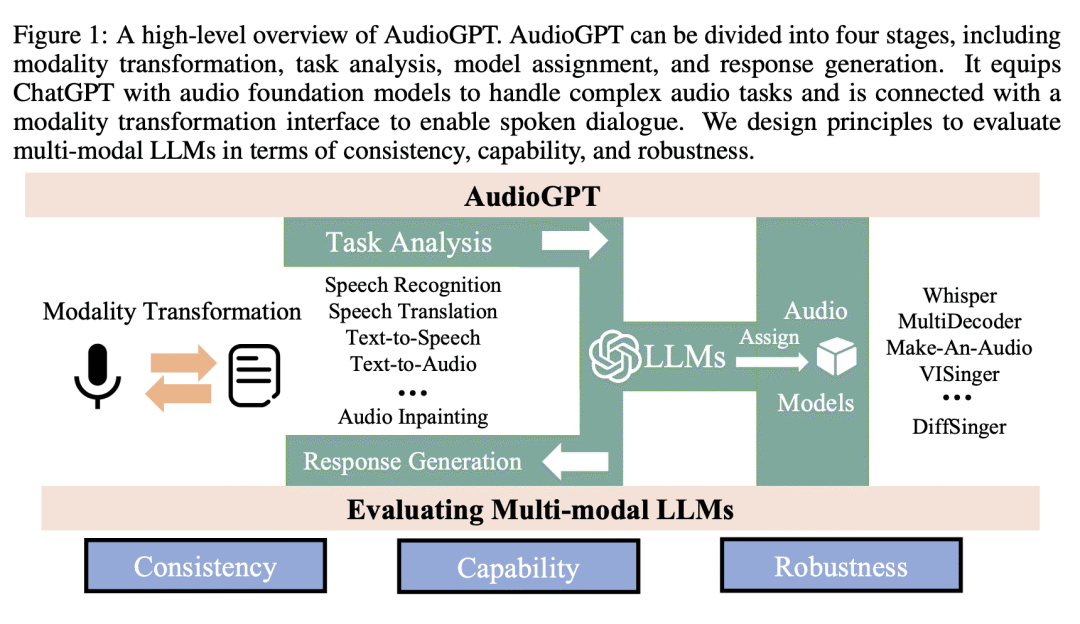
这篇论文的目标是解决当前大型语言模型(LLMs)无法处理复杂音频信息或进行口语对话的问题。论文提出了一个名为AudioGPT的多模态人工智能系统,用于处理语音、音乐、声音和讲话头的理解和生成任务。
要点:
-
动机:大型语言模型(LLM)在许多领域和任务中展现出了出色的能力,但目前无法处理复杂的音频信息或进行口头对话。本研究旨在提出一种多模态AI系统,以补充LLM的不足之处。 -
方法:AudioGPT将ChatGPT与音频基础模型和输入/输出接口相结合,以支持口头对话和处理复杂的音频任务,提出了评估多模态LLM能力的设计原则和过程。 -
优势:实验结果表明,AudioGPT在处理语音、音乐、声音和人头理解与生成等多轮对话AI任务方面具有出色的能力,使用户可以轻松地创建丰富多样的音频内容。
关键思路:
论文的解决方案是将LLMs(如ChatGPT)与基础模型相结合,以处理复杂音频信息并解决多种理解和生成任务,同时使用输入/输出接口(ASR,TTS)支持口语对话。相较于当前领域的研究,这篇论文的思路在于将LLMs与基础模型相结合,以解决复杂音频信息的处理问题。
其他亮点:
论文使用了多轮对话测试AudioGPT的一致性、能力和鲁棒性。实验结果表明,AudioGPT在解决语音、音乐、声音和讲话头理解和生成任务方面具有出色的能力,可以使人类更轻松地创建丰富多样的音频内容。此外,该系统已经公开发布在\url{https://github.com/AIGC-Audio/AudioGPT}。
关于作者:
R Huang, M Li, D Yang, J Shi, X Chang, Z Ye, Y Wu, Z Hong, J Huang, J Liu, Y Ren, Z Zhao, S Watanabe
[Zhejiang University & Peking University & CMU]
论文摘要:
本文介绍了一个名为AudioGPT的多模态人工智能系统,该系统在基于大型语言模型(LLMs)的基础上,通过引入复杂音频信息的处理模型和输入/输出接口(ASR、TTS)来实现对话交互。该系统能够处理语音、音乐、声音和虚拟人等多种信息,并在多轮对话中进行生成和理解任务,具备出色的一致性、能力和鲁棒性。
该系统的开源代码已经公开发布在\url{https://github.com/AIGC-Audio/AudioGPT} 上,可供使用。本文的研究成果为人们创造丰富多样的音频内容提供了前所未有的便利。尽管当前的LLMs已经在各种领域和任务中表现出了惊人的能力,但它们仍然无法处理复杂的音频信息或进行像Siri或Alexa那样的口语对话,因此需要像AudioGPT这样的多模态人工智能系统来补充其不足。

相关文章







