论文链接:https://arxiv.org/abs/2205.09256
代码链接:https://github.com/guilk/VLC
视觉语言Transformer(Vision-Language Transformers)一直是多模态领域中的重要研究话题,其可以同时对图像数据和语言数据进行编码,将二者在嵌入空间中对齐进而去执行下游任务。但是现有的关于视觉语言Transformer的工作仍然需要先在ImageNet上对视觉backbone进行预训练,随后再借助关键视觉目标的标注框进行引导,才可以完成视觉目标和语言描述的特征映射,这种模式使模型强依赖于预训练数据集和标注,严重限制了模型的学习能力和可扩展性。本文首先讨论了上述模式的弊端,并引入了目前较为火热的自监督Masked Auto-Encoders(MAE)[1]技术,构建了一种仅凭语言信号监督的视觉语言Transformer模型(Vision-Language from Captions,VLC),VLC在一系列的下游任务上(包括视觉问答VQA,自然语言和视觉推理NLVR和图像文本检索任务)都展现出了优越的性能。本文来自卡内基梅隆大学和微软研究院。
本文方法的设计目标是在无需有监督预训练的情况下,完成高效视觉语言Transformer模型的构建,作者在视觉ViT框架的基础上进行构建,模型的构建可以分为两个阶段,
-
首先通过图像掩码/语言嵌入进行模态内的重建自监督来学习多模态表示;
-
随后对上一步得到的多模态特征进行图像-文本匹配的模态间对齐。
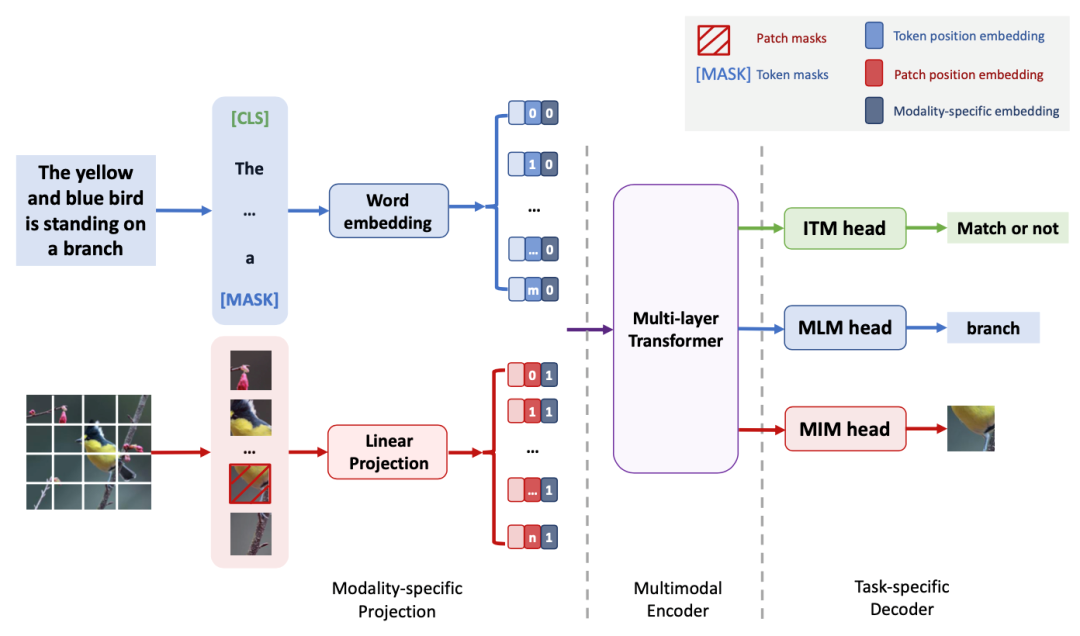
为了完成以上两个步骤,作者为VLC框架设计了三个模块,VLC框架的整体架构如下图所示,由一个模态特定的映射模块、一个多模态编码器和三个特定任务的解码器构成,图中红色和蓝色箭头分别代表图像和文本的信息流,在模态特定的映射模块中,作者使用了简单的线性投影对图像块进行编码,并设置了一个词嵌入层对来输入文本进行编码。在多模态编码器中,作者使用MAE自监督预训练(使用ImageNet-1K)的12层ViT作为编码器的主干。在任务特定的解码器模块中,作者设置了三个预训练任务,下面进行详细介绍。
[1] He, K., X. Chen, S. Xie, et al. Masked autoencoders are scalable vision learners. CVPR, 2022.
相关文章






