Pre-Training to Learn in Context
解决问题:该论文旨在通过提出一种新的框架PICL来增强语言模型的上下文学习能力,以解决在上下文中学习的能力未被充分利用的问题。该问题是一个相对新的问题。
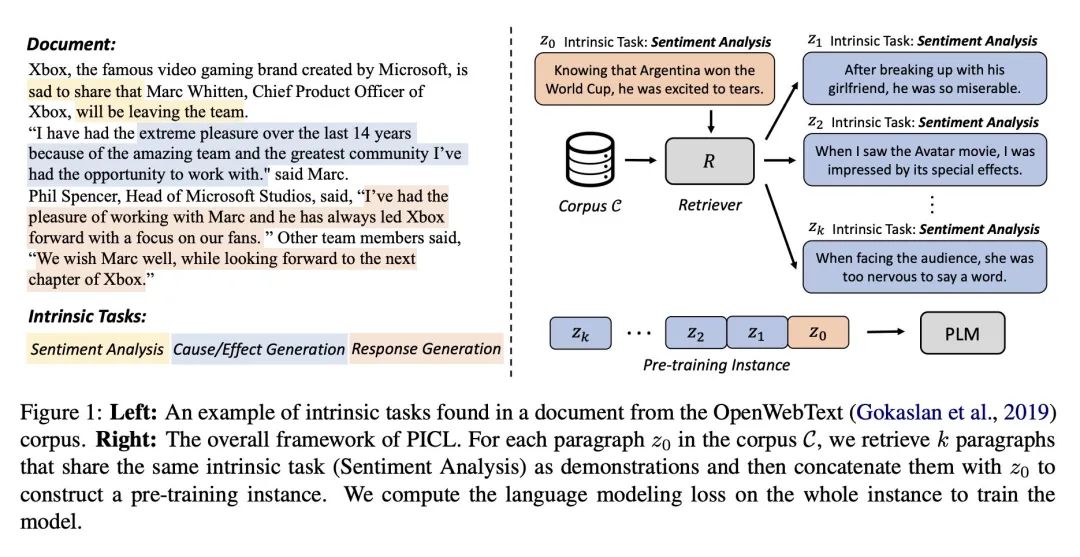
关键思路:该论文的关键思路是通过在通用纯文本语料库上使用简单的语言建模目标来对模型进行预训练,从而提高语言模型在上下文中学习的能力。PICL鼓励模型在保持预先训练模型的任务泛化的同时,通过对上下文进行条件约束来推断和执行任务。相比当前领域的研究状况,该论文提出了一种新的预训练框架,可以有效地提高模型在上下文中学习的能力。
其他亮点:该论文的实验使用了七个广泛使用的文本分类数据集和包含100多个NLP任务的Super-NaturalInstrctions基准测试来评估使用PICL训练的模型的上下文学习性能。实验结果表明,PICL比一系列基线更有效且任务泛化性更强,在参数几乎相同的情况下,比大型语言模型表现更好。
论文地址:https://arxiv.org/pdf/2305.09137.pdf
该论文的代码已公开在https://github.com/thu-coai/PICL
关于作者:Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
他们分别来自清华大学和微软亚洲研究院。他们之前的代表作包括:Yuxian Gu在ACL 2019上发表了题为“DialogWAE: Multimodal Response Generation with Conditional Wasserstein Auto-Encoder”的论文;Li Dong在ACL 2019上发表了题为“Unified Language Model Pre-training for Natural Language Understanding and Generation”的论文;Furu Wei在EMNLP 2018上发表了题为“Learning to Select Knowledge for Response Generation in Dialog Systems”的论文;Minlie Huang在ACL 2018上发表了题为“Natural Language Processing for Social Media”的论文。
论文摘要:本文介绍了一种名为PICL(Pre-training for In-Context Learning)的框架,旨在通过在通用纯文本语料库中使用简单的语言建模目标对模型进行预训练,从而增强语言模型的上下文学习能力。PICL鼓励模型在维护预训练模型的任务泛化性的同时,通过对上下文的条件加入来推断和执行任务。在七个广泛使用的文本分类数据集和包含100多个针对文本生成的NLP任务的“超自然说明”基准测试中,我们评估了使用PICL训练的模型的上下文学习性能。实验结果表明,PICL比一系列基线更有效和任务通用,参数数量几乎是更大的语言模型的4倍。该代码公开在https://github.com/thu-coai/PICL 。
相关文章






