StructGPT: A General Framework for Large Language Model to Reason over Structured Data
解决问题:本文旨在研究如何在大型语言模型中统一提高其在结构化数据上的零-shot推理能力。作者通过开发一种名为StructGPT的方法,使用迭代阅读-推理(IRR)的方式来解决基于结构化数据的问答任务。
关于作者:本文的主要作者包括Jinhao Jiang、Kun Zhou、Zican Dong、Keming Ye、Wayne Xin Zhao和Ji-Rong Wen。他们分别来自中国人民大学和电子科技大学。以前,他们在自然语言处理和人工智能领域发表了多篇代表作。
关键思路:StructGPT提出了一种迭代阅读-推理(IRR)的方法,通过构建专门的函数从结构化数据中收集相关证据(即“阅读”),并让大型语言模型集中推理任务,以收集的信息为基础进行推理(即“推理”)。此外,作者还提出了一种“调用-线性化-生成”(invoking-linearization-generation)过程,以帮助大型语言模型在外部接口的帮助下推理结构化数据。
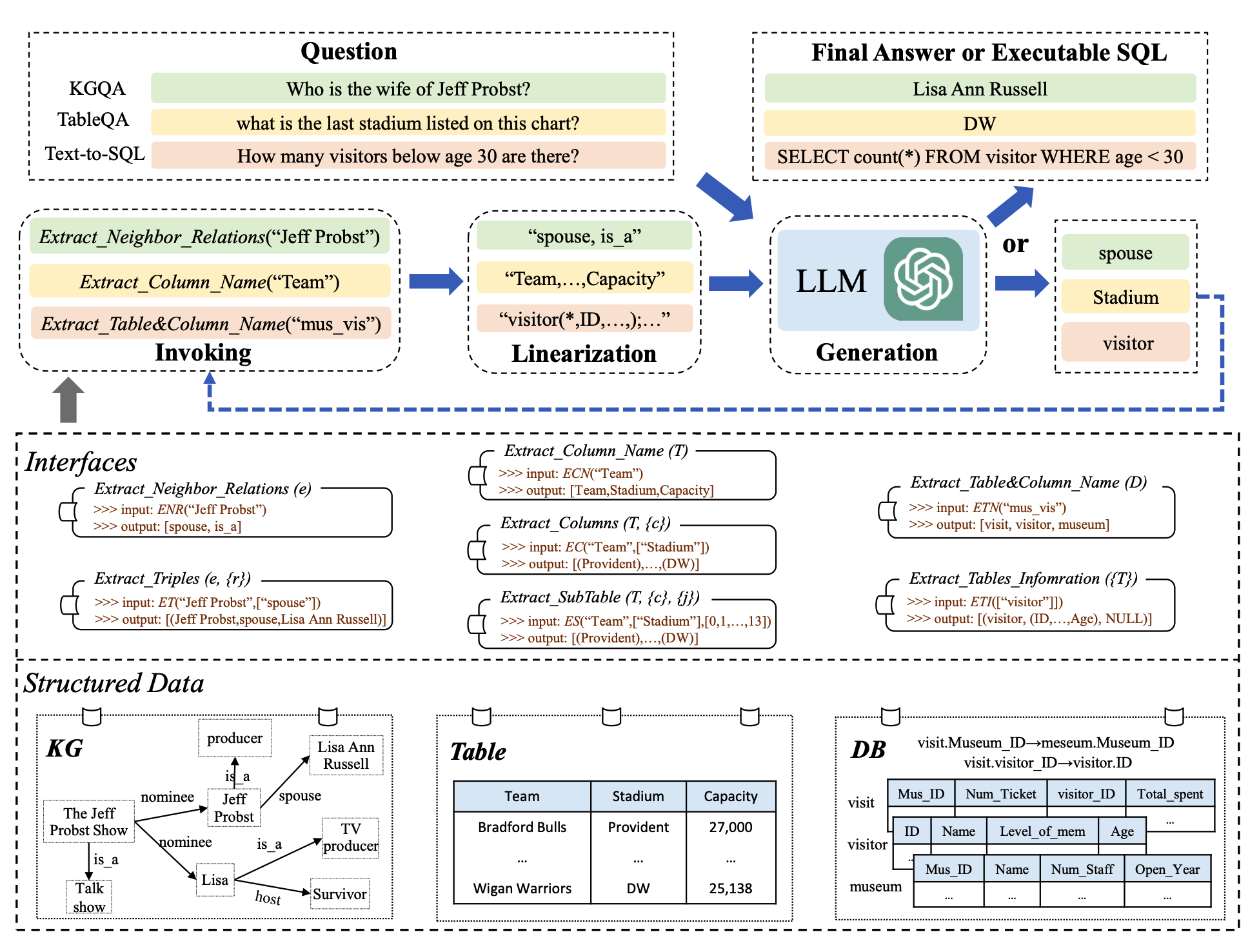
其他亮点:本文通过在三种类型的结构化数据上进行广泛的实验,证明了StructGPT方法的有效性。该方法可以显著提高ChatGPT的性能,并在与全数据监督微调基线的性能相当的情况下实现了可比较的性能。此外,作者还公开了代码和数据集。
论文摘要:本文研究如何以统一的方式提高大型语言模型(LLMs)对结构化数据进行零-shot推理的能力。受到LLMs工具增强研究的启发,我们开发了一种名为StructGPT的\emph{迭代阅读-推理(IRR)}方法,用于解决基于结构化数据的问答任务。在我们的方法中,我们构建了专门的函数来从结构化数据中收集相关证据(即\emph{阅读}),并让LLMs集中精力进行基于收集到的信息的推理任务(即\emph{推理})。特别地,我们提出了一种\emph{调用-线性化-生成}过程,以支持LLMs在外部接口的帮助下对结构化数据进行推理。通过迭代提供的接口执行这些过程,我们的方法可以逐渐接近给定查询的目标答案。在三种类型的结构化数据上进行的大量实验表明了我们方法的有效性,可以显著提高ChatGPT的性能,并实现与完整数据监督调整基线的可比性能。我们的代码和数据公开在\url{https://github.com/RUCAIBox/StructGPT}上。
论文地址:https://arxiv.org/pdf/2305.09645.pdf
GitHub地址:https://github.com/RUCAIBox/StructGPT
相关文章
