DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
Sang Michael Xie、Hieu Pham、Xuanyi Dong、Nan Du、Hanxiao Liu、Yifeng Lu、Percy Liang、Quoc V. Le、Tengyu Ma、and Adams Wei Yu
解决问题:
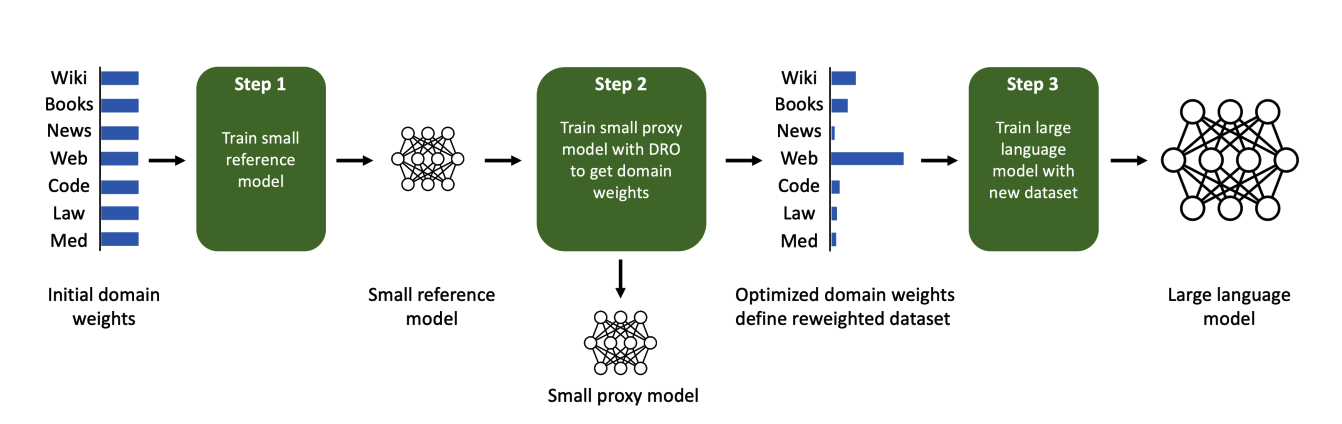
这篇论文旨在解决语言模型预训练中数据混合比例对性能的影响问题。通过提出一种名为DoReMi的方法,利用分组分布式鲁棒优化(Group DRO)训练小型代理模型来生成领域权重(混合比例),然后使用这些权重对数据集进行重新采样,并训练更大的模型。
关键思路:
DoReMi方法通过使用Group DRO算法训练小型代理模型,生成领域权重,然后使用这些权重对数据集进行重新采样,并训练更大的模型。相比于当前领域的研究,该方法的新意在于使用代理模型和Group DRO算法来生成数据混合比例,避免了需要进行多次试验的麻烦,并且不需要对下游任务进行任何先验知识。
其他亮点:
在实验中,研究人员使用DoReMi方法在一个280M参数的代理模型上找到了训练一个8B参数模型(30倍大)的混合比例,DoReMi方法在The Pile数据集上改善了所有领域的perplexity,即使它降低了某个领域的权重。DoReMi方法在平均few-shot下游准确率上比使用The Pile默认混合比例训练的基线模型提高了6.5%,并且达到了基线准确率,训练步骤少了2.6倍。在GLaM数据集上,DoReMi方法即使没有下游任务的先验知识,也能够匹配使用调整过的领域权重的性能。
论文摘要:
本文提出了一种名为DoReMi的方法,通过优化预训练数据领域的混合比例(例如Wikipedia、图书、网络文本),来提高语言模型(LM)的性能。该方法首先使用分组分布式稳健优化(Group DRO)在领域上训练一个小型代理模型,以生成领域权重(混合比例),然后使用这些领域权重重新采样数据集并训练一个更大的全尺寸模型。
DoReMi在实验中,研究人员使用DoReMi在280M参数的代理模型上,更高效地找到了训练8B参数模型的领域权重。在The Pile数据集上,DoReMi改善了所有领域的困惑度,即使它减少了某些领域的权重。相比使用The Pile默认领域权重的基线模型,DoReMi提高了平均few-shot下游准确率6.5%,并在2.6倍的训练步骤下达到了基线准确率。在GLaM数据集上,DoReMi甚至可以匹配使用下游任务调整领域权重的性能,而DoReMi并没有关于下游任务的知识。
相关文章
