
B站视频地址:
https://www.bilibili.com/video/BV18s4y1u7nJ/?spm_id_from=333.999.0.0&vd_source=cd29f4e20ef69babd26f4f34cc7c8b3f
01 作者信息
-
Timo Schick (Meta)
其他代表工作(Prompt-learning的先驱性工作)
-
It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners.
-
Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference.
-
Jane Dwivedi-Yu (Meta)
02 论文简介
-
驱动语言模型去使用简单的模型来调用外部的工具
-
Toolformer 通过语言模型的方法去决定去调用哪些 API,传入哪些参数
-
Tooformer 是在自监督层面执行的,只需要对每个 API 的语言描述
03 研究设计
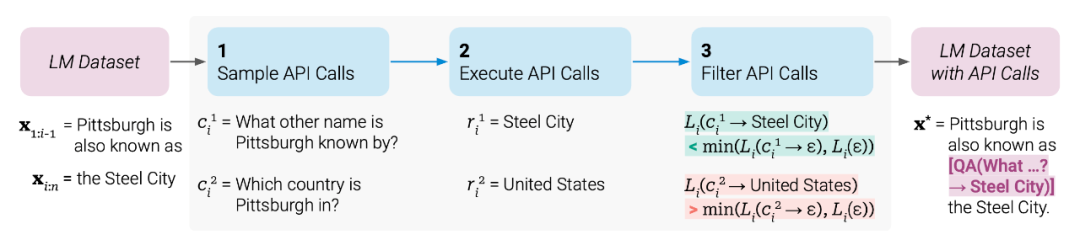
Toolformer调用示例:


-
模型应该自行地去决定在何时间,用何方法来调用工具 -
模型对工具的使用应该是自监督的,这样可以省去很大的标注开销
-
方法概要
-
受到in-context learning的启发,给定少量的人写的关于API的描述,让模型去自行生成潜在API调用的语言建模数据
-
构建一个自监督的Loss函数,让模型来决定哪些API的调用有助于它的语言建模的预测
-
具体步骤
-
给定一个纯文本数据集,构建出一个带有API调用的数据集,然后在此数据集上做微调
-
第一步:使用in-context learning来生成大量的潜在可能的API调用
-
第二步:执行这些API,返回得到结果
-
第三步:检查返回的结果是否有助于语言模型的预测,过滤掉其他的API
04 实验结果
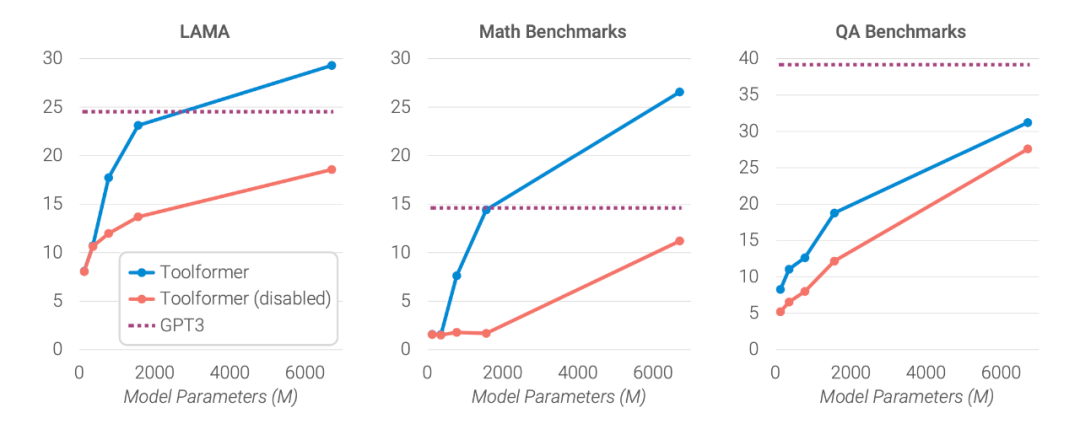
模型规模的影响
05 论文贡献
优点
-
将语言模型使用外部工具的进行很自然的结合
-
不需要标注大量数据,使用自监督的方法进行学习
缺点
-
工具无法交互,也无法链式使用(每个API调用都是独立的)
-
定义的工具尚且有限,扩展工具则需要用模型标注新的数据
-
随着基础模型zero-shot能力的增强,这种需要构建数据并且fine-tune的做法可能会比较麻烦
我们为读者准备了一份高清思维导图,包括了论文中的重点亮点以及直观的示意图。点击下方名片 关注 OpenBMB ,后台发送“论文速读” ,即可领取论文学习高清思维导图和 FreeMind !
本期论文速读视频版已发布于 OpenBMB 视频号 和 B站 (视频讲解比文字阅读更加详细易懂),欢迎大家评论和分享~
以上是本期论文速读的全部内容,后续 OpenBMB 会围绕大模型介绍更多前沿论文,欢迎大家持续关注!?
➤ 加社群/ 提建议/ 有疑问

长期开放招聘|含实习
开发岗 | 算法岗 | 产品岗
相关文章






