
2021年12月 WebGPT 的横空出世标志了基于网页搜索的问答新范式的诞生,在此之后,New Bing 首先将网页搜索功能整合发布,随后 OpenAI 也发布了支持联网的插件 ChatGPT Plugins。大模型在联网功能的加持下,回答问题的实时性和准确性都得到了飞跃式增强。
近期,面壁智能联合来自清华、人大、腾讯的研究人员 共同发布了 中文领域首个基于交互式网页搜索的问答开源模型框架 WebCPM,相关工作录用于自然语言处理顶级会议ACL 2023。WebCPM 是大模型工具学习引擎 BMTools 的首个成功实践,其特点在于其信息检索基于交互式网页搜索,能够像人类一样与搜索引擎交互从而收集回答问题所需要的事实性知识并生成答案。WebCPM 背后的基础模型 CPM 是由OpenBMB 开源社区与面壁智能开发的百亿参数中文语言模型,占据多个中文领域语言模型排行榜前列。

在当今信息化时代,人们在日常生活和工作中,需要不断地获取各种知识和信息,而这些信息往往分散在互联网上的海量数据中。如何快速、准确地获取这些信息,并且对这些信息进行合理的整合,从而回答复杂、开放式问题,是一个极具挑战性的问题。长文本开放问答(Long-form Question Answering, LFQA)模型就是为了回答这种复杂的问题而设计的。
目前的 LFQA 解决方案通常采用 检索-综合 范式,包括信息检索和信息综合两个核心环节。信息检索环节从外部知识源(如搜索引擎)中搜索多样化的相关支持事实,信息综合环节则将搜集到的事实整合成一个连贯的答案。
然而,传统的 LFQA 范式存在一个缺陷:它通常依赖于非交互式的检索方法,即 仅使用原始问题作为查询语句来检索信息。相反,人类能够通过与搜索引擎 实时交互 来进行网页搜索而筛选高质量信息。对于复杂问题,人类往往将其分解成多个子问题并依次提问。通过识别和浏览相关信息,人类逐渐完善对原问题的理解,并不断查询新问题来搜索更多样的信息。这种迭代的搜索过程有助于扩大搜索范围,提高搜索结果质量。总体而言,交互式网页搜索不仅为我们提供了获取多样化信息来源的途径,同时也反映了人类解决问题的认知过程,从而提高了可解释性。

2021年12月 OpenAI 发布 WebGPT,这是支持 LFQA 的交互式网页搜索的一项先驱性工作。作者首先构建了一个由微软必应搜索(Bing)支持的网页搜索界面,然后招募标注员使用该界面收集信息来回答问题。之后,他们微调 GPT-3模型,让其模仿人类的搜索行为,并将收集到的信息整理成答案。实验结果显示,WebGPT 在 LFQA 任务具备出色的能力,甚至超过了人类专家。而 WebGPT 也正是微软近期推出的 New Bing 背后的新一代搜索技术。
WebCPM 搜索交互界面和数据集
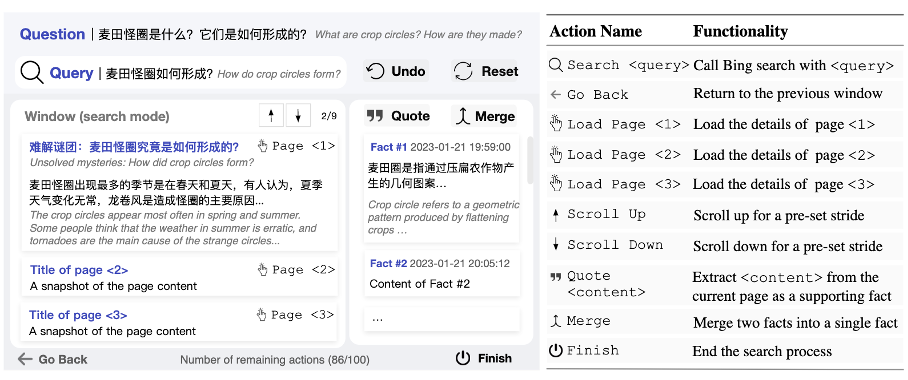
WebCPM搜索交互界面
为推动相关领域发展,这篇 ACL 论文的研究团队首先构建了一个 开源的交互式网页搜索界面,用于记录人类为开放式问题收集相关信息时的网页搜索行为。该界面底层调用必应搜索 API 支持网页搜索功能,囊括 10 种主流网页搜索操作(如点击页面、返回等等)。在这个界面中,用户可以执行预定义的操作来进行多轮搜索和浏览。在找到网页上的相关信息时,他们可以将其作为支持事实记录下来。当收集到足够的信息后,用户可以完成网页搜索,并根据收集到的事实来回答问题。同时,界面会自动记录用户的网页浏览行为,用于构建 WebCPM 数据集。
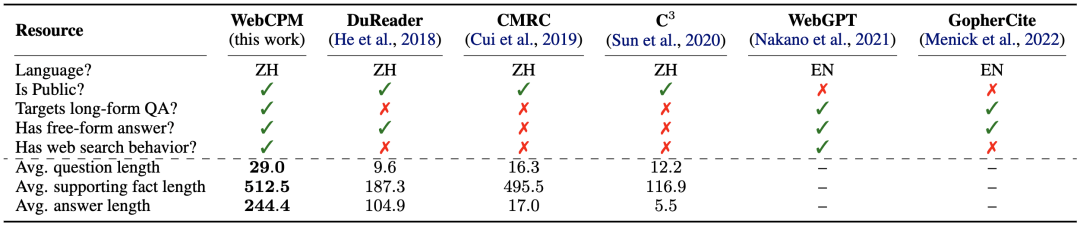
WebCPM数据集与相关问答数据集的比较
WebCPM 模型框架
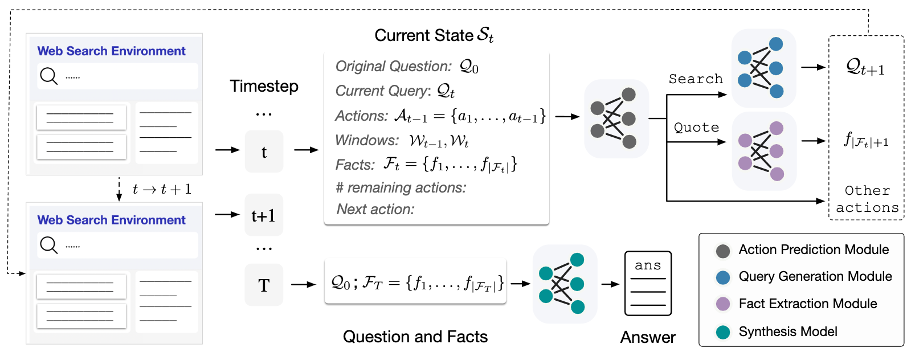
01 搜索模型
02 答案综合模型
该模型根据原问题与收集到的事实生成连贯的答案。然而与人类不同,经过训练的搜索模型偶尔会收集到不相关的噪声,这将影响生成答案的质量。为了解决这一问题,作者在答案综合模型的训练数据中引入噪声,使其具备一定的去噪的能力,从而忽略不相关的事实,只关注重要的事实以生成答案。
—
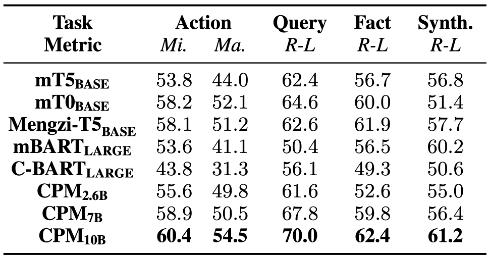
单个子任务的性能评估结果,作者测试了包括 CPM 模型在内的多个有代表性的中文大模型
? 单个子任务评估
? 整体pipeline评测
对于每个测试问题,作者比较了模型(CPM 10B模型)和人类用户使用搜索引擎回答问题和做相同任务的表现,并进行人工评测。具体而言,给定一个问题和模型与人类分别给出的答案,标注员将根据多个因素(包括答案整体实用性、连贯性和与问题的相关性)决定哪个答案更好。从下图(a)的结果可以得出以下结论:模型生成的答案在 30%+ 的情况下与人写的答案相当或更优。这个结果表明整个问答系统的性能在未来仍有巨大的提升空间(例如训练性能更加强大的基底模型);当将人工收集的事实应用于信息综合模型时,性能提高到了 45%,这可以归因于收集的事实质量的提高。
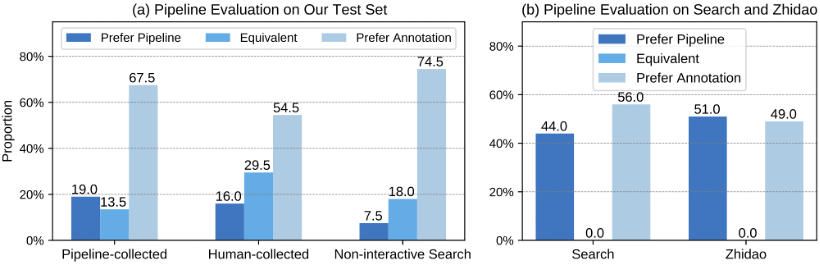
整体pipeline评测效果,作者测试了WebCPM数据集和DuReader数据集
此外,作者也将整体 pipeline 应用于 DuReader 中文 QA 数据集(包含 Zhidao 和 Search 两个子数据集),并比较了模型生成的答案和人工标注的答案,从上图(b)可以观察到模型生成的答案比 DuReader 标注答案更好的情况接近 50%,这反映了该模型强大的泛化能力,体现了 WebCPM 数据标注的高质量。
WebCPM 案例分析
—
为了探究查询模块所学习到的人类行为,作者抽样不同测试问题生成的查询语句来进行案例分析。下图展示了部分结果,以研究查询模块的性能。可以看出,该模块已经学会了 复制原始问题,将问题分解为多个子问题,用相关术语改写问题 等多种人类搜索策略。这些策略使查询语句更加多样化,有助于从更多的来源收集更丰富的信息。

WebCPM 成功实践 BMTools
—
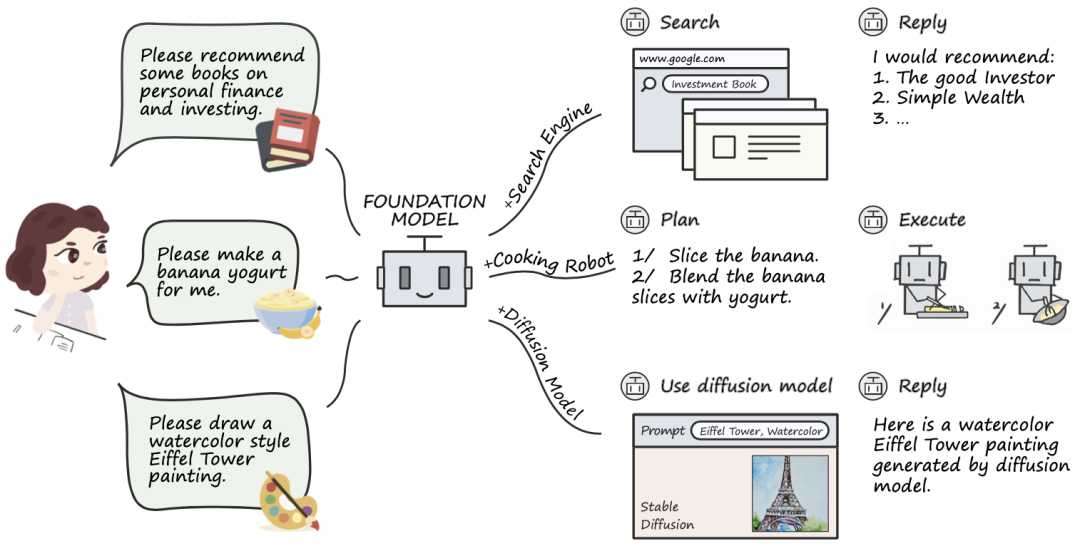 近年来,大模型在诸多领域展现出惊人的应用价值,持续刷新各类下游任务的效果上限。尽管大模型在很多方面取得了显著的成果,但在特定领域的任务上,仍然存在一定的局限性。这些任务往往需要专业化的工具或领域知识才能有效解决。因此,大模型需要具备调用各种专业化工具的能力,这样才能为现实世界任务提供更为全面的支持。最近,新的范式 大模型工具学习(Tool Learning)应运而生。这一范式的核心在于将专业工具与基础模型的优势相融合,以在问题解决方面达到更高的准确性、效率和自主性,工具学习极大地释放了大模型的潜力。
近年来,大模型在诸多领域展现出惊人的应用价值,持续刷新各类下游任务的效果上限。尽管大模型在很多方面取得了显著的成果,但在特定领域的任务上,仍然存在一定的局限性。这些任务往往需要专业化的工具或领域知识才能有效解决。因此,大模型需要具备调用各种专业化工具的能力,这样才能为现实世界任务提供更为全面的支持。最近,新的范式 大模型工具学习(Tool Learning)应运而生。这一范式的核心在于将专业工具与基础模型的优势相融合,以在问题解决方面达到更高的准确性、效率和自主性,工具学习极大地释放了大模型的潜力。
在应用方面,ChatGPT Plugins 的出现补充了 ChatGPT 最后的短板,使其可以支持连网、解决数学计算,被称为OpenAI的“App Store”时刻。然而直到现在,它仅支持部分OpenAI Plus用户,大多数开发者仍然无法使用。为此,OpenBMB和面壁智能前段时间也推出了工具学习引擎 BMTools,一个基于语言模型的开源可扩展工具学习平台,它是我们在大模型体系布局中的又一重要模块。研发团队将各种各样的工具(例如文生图模型、搜索引擎、股票查询等)调用流程都统一到一个框架上,使整个工具调用流程标准化、自动化。开发者可以通过 BMTools,使用给定的模型(ChatGPT、GPT-4)调用多种多样的工具接口,实现特定功能。此外,BMTools 工具包也已集成最近爆火的 Auto-GPT 与 BabyAGI。
WebCPM 是 BMTools 的一次成功实践,相信在不断发展和完善大模型工具学习技术的过程中,我们将让大模型落地赋能更多产业。期待大模型在更多领域展现出令人惊喜的应用价值!
➤ 传送门 BMTools
? https://github.com/OpenBMB/BMTools
➤ 传送门 OpenBMB 主页
➤ 加社群/ 提建议/ 有疑问
请找 OpenBMB 万能小助手:

长期开放招聘|含实习
开发岗 | 算法岗 | 产品岗

https://www.openbmb.org
技术文章
多智能体开源平台 AgentVerse | Tool learning 权威综述
Delta Tuning 登陆 Nature子刊 | 大模型工具学习引擎 BMTools
CPM-Ant 训练完成 | BMInf 适配GLM-130B
高效训练工具 BMTrain | BMTrain 技术原理
CPM-Live 邀请函 | CPM-Live 训练启动
OpenBMB 社区介绍 | 大模型课程
大模型榜单 BMList


相关文章






