Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, Christian Theobalt
分别来自马克斯・普朗克计算机科学研究,萨尔布吕肯视觉计算、交互与AI研究中心,MIT,宾夕法尼亚大学和谷歌AR/VR部门,论文已入选SIGGRAPH 2023。
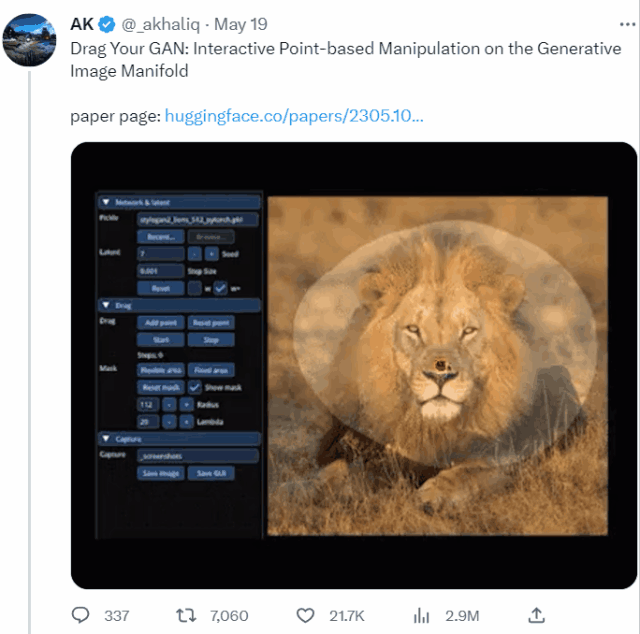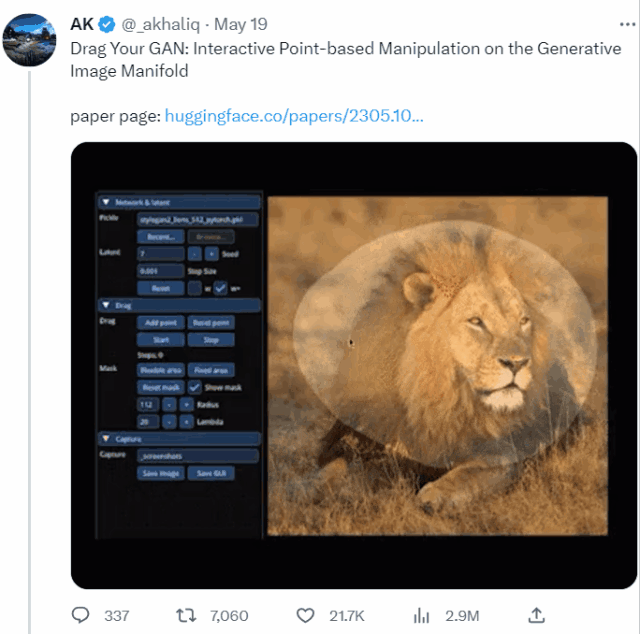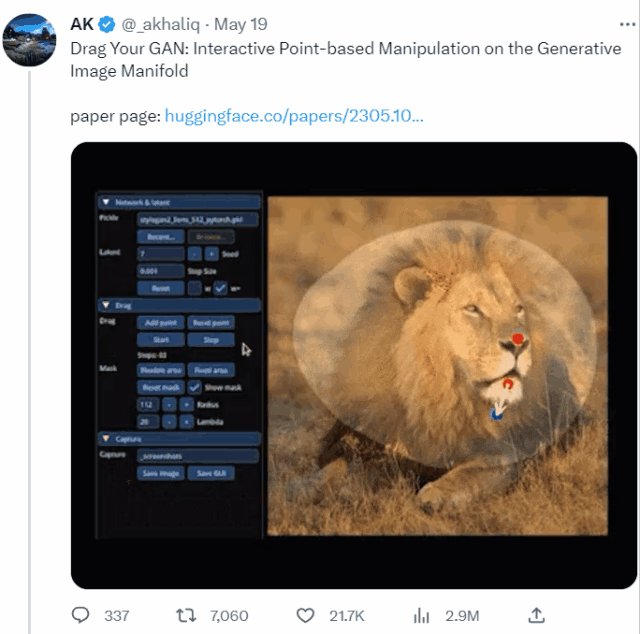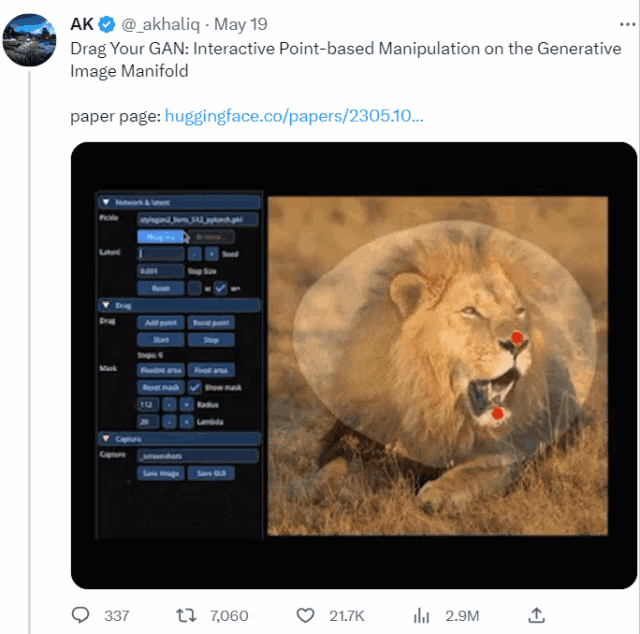
本篇论文旨在解决生成对抗网络(GAN)中控制生成图像的问题。通过“拖动”图像中的任意点,实现用户交互式精确控制生成图像的姿态、形状、表情和布局。
这个名叫DragGAN的模型,本质上是为各种GAN开发的一种交互式图像操作方法。论文以StyleGAN2架构为基础,实现了点点鼠标、拽一拽关键点就能P图的效果。
通过两个主要组件实现GAN的交互式控制:1)基于特征的运动监督,驱动手柄点向目标位置移动;2)新的点跟踪方法,利用辨别式生成器特征来不断定位手柄点的位置。与现有方法相比,DragGAN不需要手动注释训练数据或先验3D模型,具有更高的灵活性、精度和通用性。实验结果表明,DragGAN在图像操纵和点跟踪任务中优于先前的方法。同时,本文还展示了通过GAN反演对真实图像进行操纵的能力。作者开源了代码和数据集,为后续研究提供了便利。

运动监督
业界还没有太多关于如何监督GAN生成图像的点运动的研究。在这项研究中,作者提出了一种不依赖于任何额外神经网络的运动监督损失(loss)。其关键思想是,生成器的中间特征具有很强的鉴别能力,因此一个简单的损失就足以监督运动。
所以,DragGAN的运动监督是通过生成器特征图上的偏移补丁损失(shifted patch loss)来实现的。
点跟踪
先前的运动监督会产生一个新的latent code、一个新特征图和新图像。由于运动监督步骤不容易提供控制点的精确新位置,因此我们的目标是更新每个手柄点p使其跟踪上对象上的对应点。
此前,点跟踪通常通过光流估计模型或粒子视频方法实现。但同样,这些额外的模型可能会严重影响效率,并且在GAN模型中存在伪影的情况下可能使模型遭受累积误差。
因此,作者提供了一种新方法,该方法通过最近邻检索在相同的特征空间上进行点跟踪。
而这主要是因为GAN模型的判别特征可以很好地捕捉到密集对应关系。基于这以上两大组件,DragGAN就能通过精确控制像素的位置,来操纵不同类别的对象完成姿势、形状、布局等方面的变形。
作者表示,由于这些变形都是在GAN学习的图像流形上进行的,它遵从底层的目标结构,因此面对一些复杂的任务(比如有遮挡),DragGAN也能产生逼真的输出。
由于这些操作是在GAN学习的生成图像流形上执行的,因此它们往往可以产生逼真的输出,即使是在挑战性场景下,如幻觉遮挡内容和形状变形,也能保持对象的刚性。定性和定量比较表明,在图像操作和点追踪任务中,DragGAN相对于先前的方法具有优势。研究人员还展示了通过GAN反演来操纵真实图像的能力。
关于作者
一作潘新钢,他本科毕业于清华大学(2016年),博士毕业于香港中文大学(2021年),师从汤晓鸥教授。现在是马普计算机科学研究所的博士后,今年6月,他将进入南洋理工大学担任助理教授(正在招收博士学生)
Liu Lingjie,香港大学博士毕业(2019年),后在马普信息学研究所做博士后研究,现在是宾夕法尼亚大学助理教授(也在招学生),领导该校计算机图形实验室,也是通用机器人、自动化、传感与感知 (GRASP)实验室成员。
论文地址:
https://vcai.mpi-inf.mpg.de/projects/DragGAN/data/paper.pdf
项目地址(代码6月开源):
https://github.com/XingangPan/DragGAN
相关文章
