近年来,基于惯性的人体动作捕捉技术迅速发展。它们通过在人体上穿戴惯性传感器,实时测量人体的运动信息。然而,这就好比一个人在蒙着眼睛走路——我们可以感受到身体的运动,但随着时间的累积,我们越来越难以确定自己的位置。
本文则试图打开惯性动作捕捉的「眼睛」。通过额外佩戴一个手机相机,我们的算法便有了「视觉」。它可以在捕获人体运动的同时感知环境信息,进而实现对人体的精确定位。该项研究来自清华大学徐枫团队,已被计算机图形学领域国际顶级会议SIGGRAPH2023接收。

-
论文地址:https://arxiv.org/abs/2305.01599
-
项目主页:https://xinyu-yi.github.io/EgoLocate/
-
开源代码:https://github.com/Xinyu-Yi/EgoLocate
简介
随着计算机技术的发展,人体感知和环境感知已经成为现代智能应用中不可或缺的两部分。人体感知技术通过捕捉人体运动和动作,可以实现人机交互、智能医疗、游戏等应用。而环境感知技术则通过重建场景模型,可以实现三维重建、场景分析和智能导航等应用。两个任务相互依赖,然而国内外现有技术大多独立地处理它们。研究团队认为,人体运动和环境的组合感知对于人类与环境互动的场景非常重要。首先,人体和环境同时感知可以提高人类与环境互动的效率和安全性。例如,在自动驾驶汽车中,同时感知驾驶员的行为和周围环境可以更好地保证驾驶的安全性和顺畅性。其次,人体和环境同时感知可以实现更高级别的人机交互,例如,在虚拟现实和增强现实中,同时感知用户的动作和周围环境可以更好地实现沉浸式的体验。因此,人体和环境同时感知可以为我们带来更高效、更安全、更智能的人机交互和环境应用体验。
基于此,清华大学徐枫团队提出了仅使用6个惯性传感器(IMU)和1个单目彩色相机的同时实时人体动作捕捉、定位和环境建图技术(如图1所示)。惯性动作捕捉(mocap)技术探索人体运动信号等「内部」信息,而同时定位与建图(SLAM)技术主要依赖「外部」信息,即相机捕捉的环境。前者具有良好的稳定性,但由于没有外部正确的参考,全局位置漂移在长时间运动中会累积;后者可以高精度地估计场景中的全局位置,但当环境信息不可靠时(例如没有纹理或存在遮挡),就容易出现跟踪丢失。
因此,本文有效将这两种互补的技术(mocap和SLAM)结合起来。通过在多个关键算法上进行人体运动先验和视觉跟踪的融合,实现了鲁棒和精确的人体定位和地图重建。
图1 本文提出同时人体动作捕捉与环境建图技术
具体地,本研究将6个IMU穿戴在人的四肢、头和后背上,单目彩色相机固定在头部并向外拍摄。这种设计受到真实人类行为的启发:当人类处于新环境中时,他们通过眼睛观察环境并确定自己的位置,从而在场景中计划他们的运动。
在我们的系统中,单目相机充当人类的眼睛,为本技术提供实时场景重建和自我定位的视觉信号,而IMU则测量人体四肢和头部的运动。这套设置兼容现有VR设备,可利用VR头显中的相机和额外佩戴的IMU进行稳定无漂移的全身动捕和环境感知。整个系统首次实现了仅基于6个IMU和1个相机的同时人体动作捕捉和环境稀疏点重建,运行速度在CPU上达到60fps,并在精度上同时超过了两个领域最先进的技术。该系统的实时示例如图2和图3所示。
图2 在70米的复杂运动中,本系统精确跟踪人体位置并捕捉人体动作,无明显位置漂移。
图3 本系统同时重建人体运动和场景稀疏点的实时示例。
实验
对比Mocap
本文方法主要解决了稀疏惯性动作捕捉(Mocap)中全局位置漂移的问题,因此选取主要测试指标为人体全局位置误差。在TotalCapture和HPS两个公开数据集上和SOTA mocap方法TransPose[3]、TIP[4]和PIP[1]的定量测试结果对比如下表1所示,定性测试结果对比如下图7和图8所示。可以看到本文方法在全局定位精度上大幅超过前人惯性动作捕捉方法(在TotalCapture和HPS上分别提升41%和38%),轨迹与真值的相似度最高。
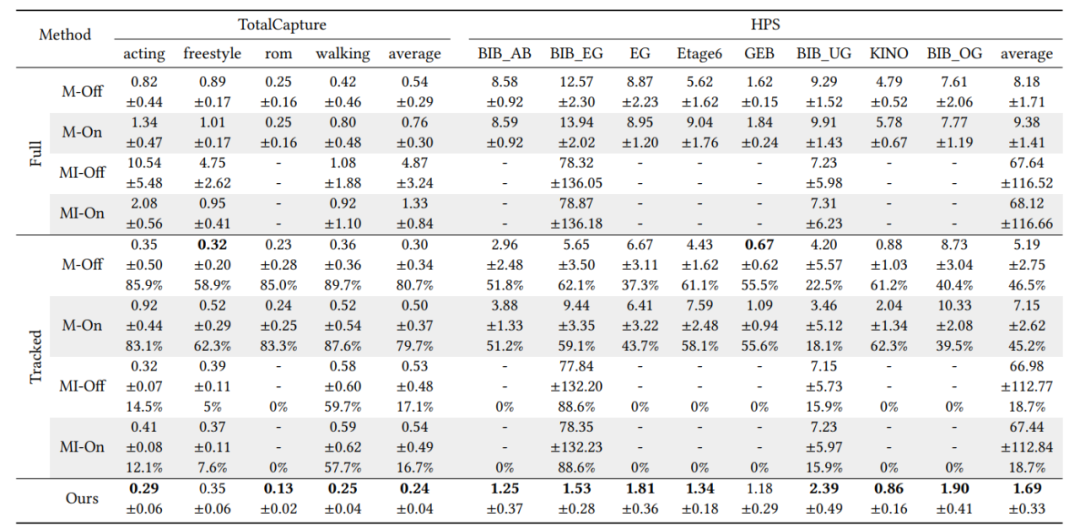
表1 和惯性动作捕捉工作的全局位置误差定量对比(单位:米)。TotalCapture数据集以动作进行分类,HPS数据集以场景进行分类。针对我们的工作,我们测试9次并汇报中位数和标准差。
图7 和惯性动作捕捉工作的全局位置误差定性对比。真值用绿色表示,不同方法预测结果用蓝色表示。每个图片的角落中展示了人体的运动轨迹和当前位置(橙色圆点)。
图8 和惯性动作捕捉工作的全局位置误差定性对比(视频)。真值用绿色表示,本文方法为白色,前人工作的方法使用其他不同颜色(见图例)。
对比SLAM
本文从定位精度和地图重建精度两个角度分别和SOTA SLAM工作ORB-SLAM3[2]的单目和单目惯性版本进行了对比。定位精度的定量对比结果如表2所示。地图重建精度的定量对比结果如表3所示,定性对比结果如图9所示。可以看到,本文方法相比SLAM大幅提高了系统鲁棒性、定位精度和地图重建精度。
表2 和SLAM工作的定位误差定量对比(误差单位:米)。M/MI分别表示ORB-SLAM3的单目/单目惯性版本,On/Off表示SLAM的实时和离线结果。由于SLAM经常跟踪丢失,针对SLAM我们分别汇报了完整序列(Full)和成功跟踪的帧(Tracked)上的平均定位误差;本文方法不存在跟踪丢失情况,因此我们汇报完整序列的结果。每个方法测试9次并汇报中位数和标准差。对于成功跟踪的帧上的误差,我们额外汇报了成功的百分比。如果一个方法失败过多次,我们标记它为失败(用“-”表示)。
表3 和SLAM工作的地图重建误差定量对比(误差单位:米)。M/MI分别表示ORB-SLAM3的单目/单目惯性版本。针对三个不同场景(办公室、室外、工厂),我们测试所有重建的3D地图点距离场景表面几何的平均误差。每个方法测试9次并汇报中位数和标准差。如果一个方法失败过多次,我们标记它为失败(用“-”表示)。
图9 和SLAM工作的地图重建误差定性对比。我们展示了不同方法重建的场景点,颜色表示每个点的误差。
除此之外,本系统通过引入人体运动先验,针对视觉跟踪丢失的鲁棒性大幅提高。在视觉特征较差时,本系统可以利用人体运动先验持续跟踪,而不会像其他SLAM系统一样跟踪丢失并重置或创建新地图。如下图10所示。
图10 和SLAM工作的遮挡鲁棒性比较。右上角展示了真值轨迹参考。由于SLAM初始化的随机性,全局坐标系和时间戳没有完全对齐。
关于更多的实验结果,请参考论文原文、项目主页及论文视频。
总结
本文提出了第一个将惯性动作捕捉 (inertial mocap) 与 SLAM 相结合,实现实时同时进行人体动作捕捉、定位和建图的工作。该系统足够轻量,只需要人体穿戴稀疏的传感器,包括 6 个惯性测量单元和一个手机相机。对于在线跟踪,mocap 和 SLAM 通过约束优化和 Kalman 滤波技术进行融合,从而实现更准确的人体定位。对于后端优化,通过将人体运动先验融入SLAM 中的光束平差优化和闭环优化,进一步减少定位和建图误差。
本研究旨在将人体感知与环境的感知融合在一起。尽管本工作主要关注定位方面,但我们相信,这项工作迈出了联合运动捕捉和精细环境感知与重建的第一步。
[1] Xinyu Yi, Yuxiao Zhou, Marc Habermann, Soshi Shimada, Vladislav Golyanik, Christian Theobalt, and Feng Xu. 2022. Physical Inertial Poser (PIP): Physics-aware Real-time Human Motion Tracking from Sparse Inertial Sensors. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
[2] Carlos Campos, Richard Elvira, Juan J. Gómez, José M. M. Montiel, and Juan D. Tardós. 2021. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM. IEEE Transactions on Robotics 37, 6 (2021), 1874–1890.
[3] Xinyu Yi, Yuxiao Zhou, and Feng Xu. 2021. TransPose: Real-time 3D Human Translation and Pose Estimation with Six Inertial Sensors. ACM Transactions on Graphics 40 (08 2021).
[4] Yifeng Jiang, Yuting Ye, Deepak Gopinath, Jungdam Won, Alexander W. Winkler, and C. Karen Liu. 2022. Transformer Inertial Poser: Real-Time Human Motion Reconstruction from Sparse IMUs with Simultaneous Terrain Generation. In SIGGRAPH Asia 2022 Conference Papers