?智源社区日报关注订阅?
Fine-Tuning Language Models with Just Forward Passes
Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D. Lee, Danqi Chen, Sanjeev Arora
陈丹琦,普林斯顿大学计算机科学助理教授,西雅图Facebook AI Research(FAIR)的访问科学家。2018年,获得在斯坦福大学计算机科学系获得博士学位。
本文旨在介绍一种用于fine-tuning语言模型(LM)的低内存优化器——MeZO,内存减少多达12倍。使用单个A100 800G GPU,MeZO可以训练一个300亿参数的模型。
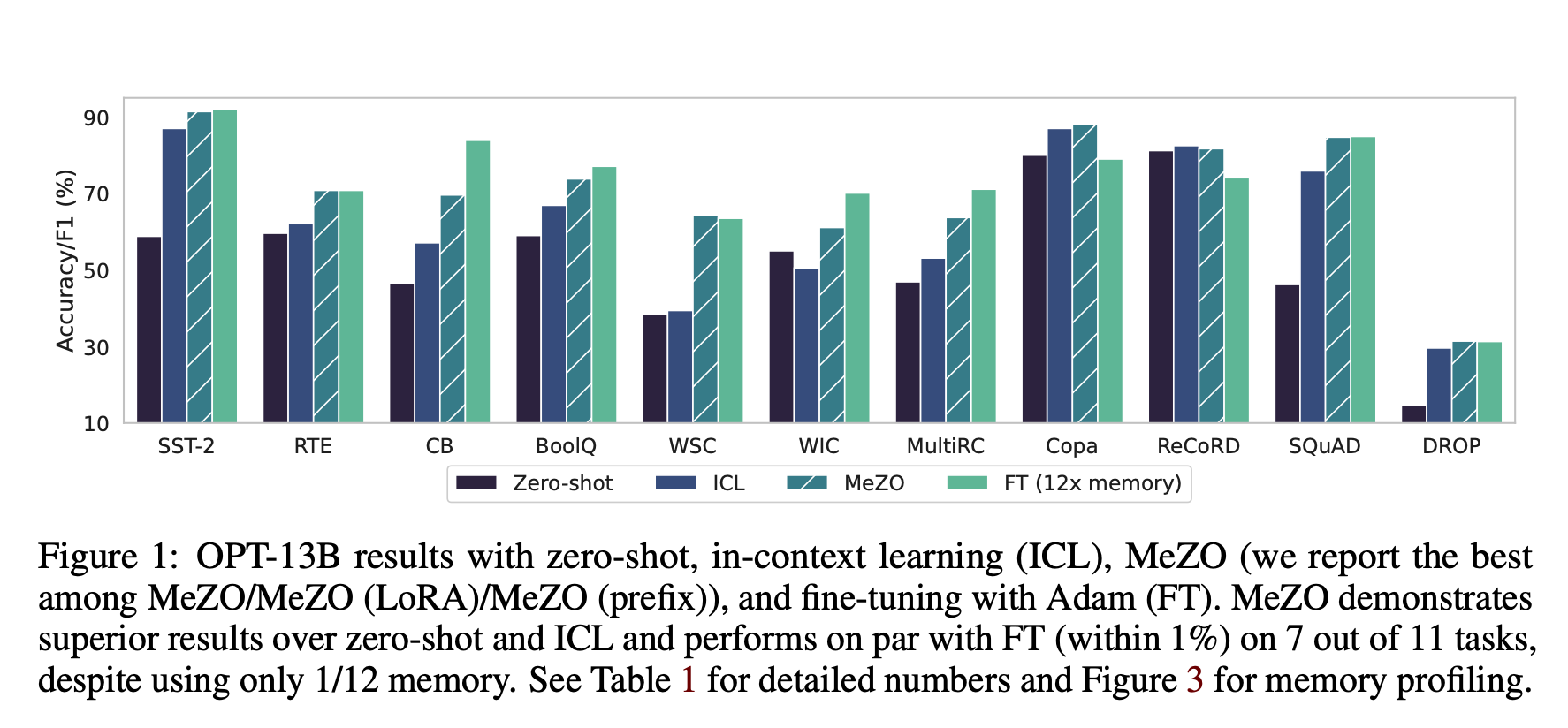
本文提出了一个用于微调语言模型(LM)的内存高效的零阶优化器(MeZO)。随着LM的变大,反向传播变得计算成本高昂,需要大量的内存。MeZO采用经典的零阶随机梯度下降(ZO-SGD)方法,以就地运行,从而能够以与推断相同的内存占用空间对LM进行微调。
例如,使用单个A100 80GB GPU,MeZO可以训练300亿参数模型,而反向传播的微调只能用相同的资源训练27亿参数LM。MeZO已被证明可以与多个任务的反向传播相当,使内存使用量减少了12倍。
此外,MeZO在优化非可微目标方面非常有效,这些目标通常与反向传播不兼容。作者提供了理论上的见解,为什么尽管处理了数十亿个参数,但MeZO并不非常慢,正如经典的ZO理论所表明的那样。
作者还强调了未来潜在的探索领域,包括将MeZO与其他内存高效方法相结合,以及其对修剪、蒸馏、显著性、可解释性和用于微调的数据集选择等各种领域的适用性。
论文:https://arxiv.org/abs/2305.17333
代码:https://github.com/princeton-nlp/mezo
微调语言模型(LM)在各种下游任务上取得了成功,但随着LM的规模增长,反向传播需要大量内存。零阶(ZO)方法原则上只能使用两个正向传球来估计梯度,但理论上在优化大型模型时会非常缓慢。在这项工作中,我们提出了一个内存高效的零阶优化器(MeZO),将经典的ZO-SGD方法应用于就地运行,从而以与推断相同的内存占用来微调LM。
例如,使用单个A100 80GB GPU,MeZO可以训练300亿参数模型,而反向传播的微调只能以相同的预算训练2.7B LM。我们跨模型类型(屏蔽和自回归LM)、模型规模(高达66B)和下游任务(分类、多项选择和生成)进行全面实验。我们的结果表明,(1)MeZO的表现明显优于上下文学习和线性探测;(2)MeZO实现了与跨多个任务的反向传播微调的类似性能,内存减少高达12倍;(3)MeZO与全参数和参数高效的调优技术兼容,如LoRA和前缀调优;(4)MeZO可以有效地优化非可微的目标(例如,最大限度地提高准确性或F1)。我们用理论见解支持我们的实证发现,强调尽管经典的ZO分析表明情况并非如此,但充分的预培训和任务提示如何使MeZO能够微调大型模型。
相关资讯:
https://www.reddit.com/r/MachineLearning/comments/13wgwo2/r_finetuning_language_models_with_just_forward/
相关文章
