
-
项目主页: https://panda-gpt.github.io/
-
代码: https://github.com/yxuansu/PandaGPT
-
论文: http://arxiv.org/abs/2305.16355
-
线上 Demo 展示: https://huggingface.co/spaces/GMFTBY/PandaGPT
-
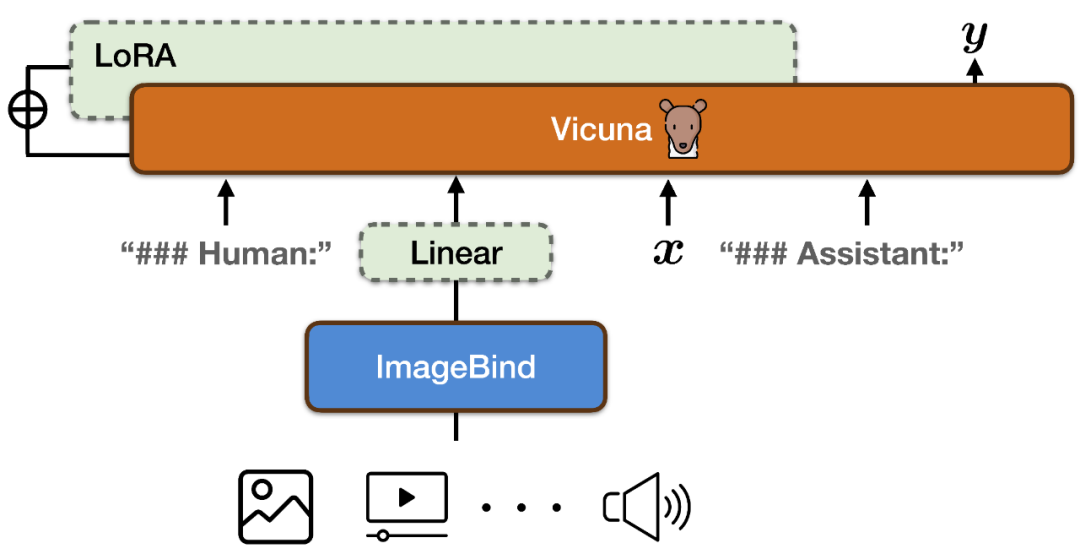
在 ImageBind 的编码结果上新增一个线性投影矩阵,将 ImageBind 生成的表示转换后插入到 Vicuna 的输入序列中;
-
在 Vicuna 的注意力模块上添加了额外的 LoRA 权重。两者参数总数约占 Vicuna 参数的 0.4%。训练函数为传统的语言建模目标。值得注意的是,训练过程中仅对模型输出对应部分进行权重更新,不对用户输入部分进行计算。整个训练过程在 8×A100 (40G) GPUs 上完成训练需要约 7 小时。



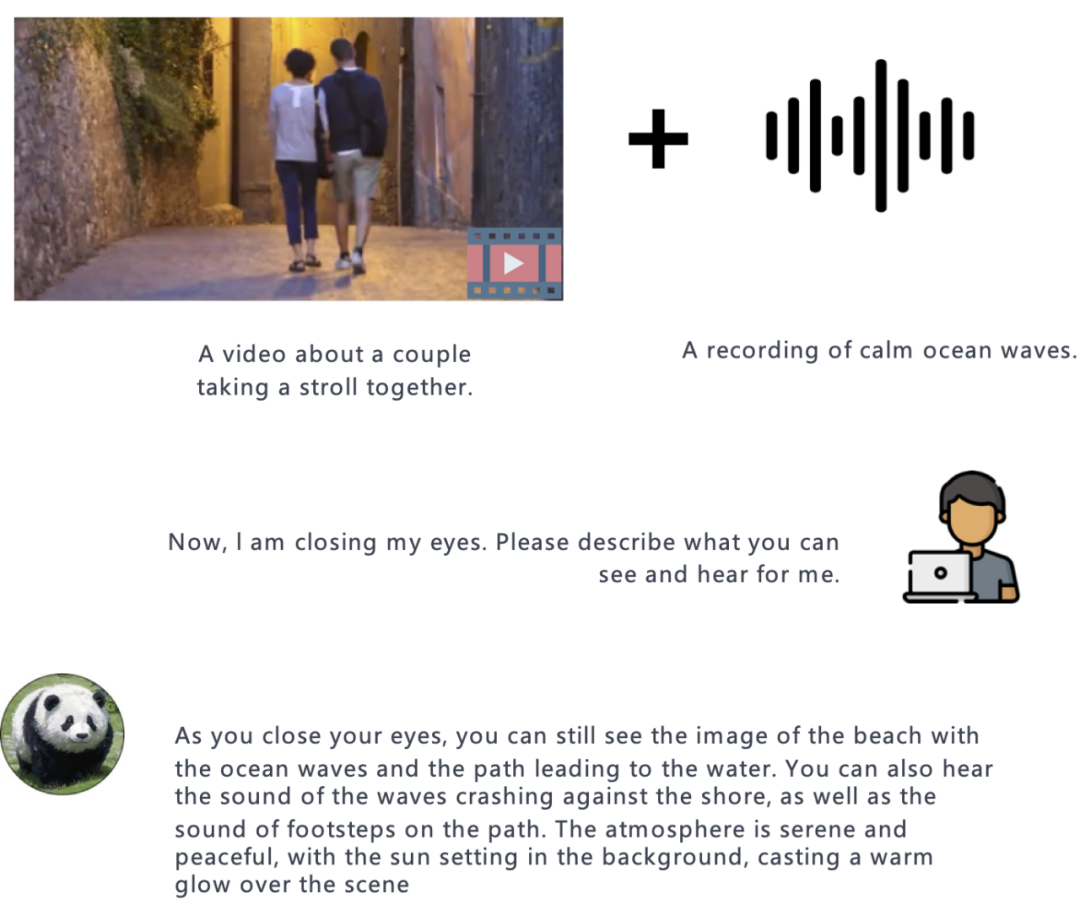
图像 + 音频:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






这是一个专注于人工智能产品的导航站。
