?智源社区日报关注订阅?
Digital Renaissance: NVIDIA Neuralangelo Research Reconstructs 3D Scenes
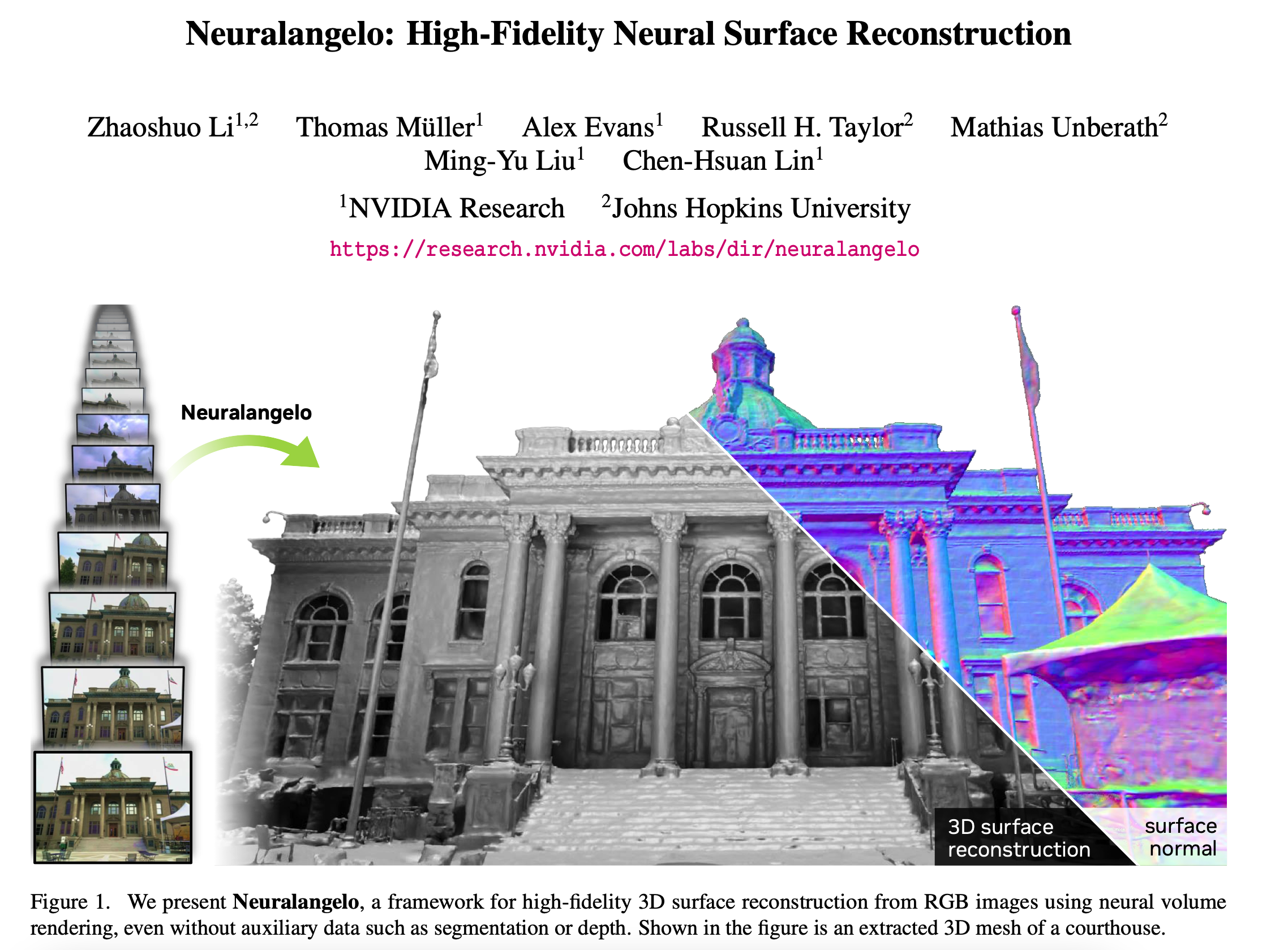
英伟达团队提出Neuralangelo,从2D视频重建3D大规模场景,将5.5米大卫雕像完美复刻,利用神经网络重建3D物体。
这是将多分辨率3D哈希网格的表征能力和神经表面渲染相结合的全新方法,已被CVPR 2023录用。Neuralangelo可以从手机视频,无人机拍摄的视频重建「高保真的大规模场景」。
https://d1qx31qr3h6wln.cloudfront.net/publications/Li_Neuralangelo_High-Fidelity_Neural_Surface_Reconstruction_CVPR_2023_paper.pdf
这篇论文采用的架构名叫Neuralangelo,著名雕塑家米开朗基罗(Michelangelo)的名字。
神经表面重建已被证明对通过基于图像的神经渲染恢复密集的3D表面非常有效。然而,目前的方法很难恢复现实世界场景的详细结构。为了解决这个问题,我们介绍了Neuralangelo,它将多分辨率3D散列网格的表示能力与神经表面渲染相结合。
两个关键因素使我们的方法成为可能:(1)计算高阶导数的数值梯度作为平滑操作,以及(2)控制不同细节水平的散列网格上的粗到细优化。即使没有深度等辅助输入,Neuralangelo也可以有效地从多视图图像中恢复密集的3D表面结构,保真度大大超过以前的方法,从而从RGB视频捕获中实现详细的大规模场景重建。
关于作者
Zhaoshuo Li 、Thomas Müller、Alex Evans、Russell H. Taylor、 Mathias Unberath、 Ming-Yu Liu、Chen-Hsuan Lin
英伟达研究院和约翰霍普金斯大学
李赵硕(Zhaoshuo Li)
本科毕业于不列颠哥伦比亚大学,目前是约翰霍普金斯大学的博士生,师从Mathias Unberath和Russell Taylor,本科专业也是机器人工程,如今算是小小跨界,研究重点在图像重建3D结构上。Neuralangelo是李赵硕在英伟达实习期间的工作。此前,他还曾在Meta的Reality Labs实习。
Thomas https://tom94.net
Thomas是NVIDIA的首席研究科学家,致力于机器学习和(反向)光传输模拟的交叉点。他的研究赢得了多个最佳论文奖,在《时代周刊》的2022年最佳发明中亮相,并用于电影制作、商业3D重建和游戏。作为研究的一部分,Thomas创建并积极维护了几个广泛使用的开源框架,包括神经图形和3D重建工具instant-ngp、高速机器学习框架tiny-cuda-nn和图像比较工具tev。Thomas拥有苏黎世联邦理工学院和迪士尼研究院的博士学位,在过去的生活中,他还开发了在线节奏游戏“osu!”的大量组件。
Russell Taylor
医疗机器人领域泰斗,曾主持研发全球首台骨科手术机器人ROBDOC。
劉洺堉 https://mingyuliu.net
NVIDIA Research的研究总监。研究重点是深度生成模型及其应用。我想让机器拥有超人的想象力,这样他们就可以更好地帮助我们创建内容和表达自己。我喜欢把我的研究交到人们的手中。NVIDIA GauGAN/Canvas和NVIDIA Maxine是我的研究创造的两款产品。我考虑让研究界更好地成为我使命的一部分。我经常担任各种顶级人工智能会议的区域主席,包括NeurIPS、ICML、ICLR、CVPR、ICCV和ECCV,并在我的领域组织教程和研讨会。在许多人的推动下,我在我的领域赢得了几个主要奖项,包括两次获得SIGGRAPH最佳表演奖。
陈轩林 https://chenhsuanlin.bitbucket.io/
是英伟达研究院的研究科学家。他在卡内基梅隆大学获得机器人博士学位,在那里他得到了Simon Lucey教授的建议,并得到了NVIDIA研究生奖学金的支持。他的研究兴趣是计算机视觉、计算机图形学和机器学习,重点是3D重建、视图合成、神经渲染和生成模型。在博士期间,他通过研究实习在Adobe Research和Facebook AI Research(FAIR)工作。他获得了CMU的机器人学硕士学位和国立台湾大学的电气工程学士学位。
以下为英伟达官网博客内容,机器翻译
原文请移步:
https://blogs.nvidia.com/blog/2023/06/01/neuralangelo-ai-research-3d-reconstruction/
Neuralangelo是NVIDIA Research使用神经网络进行3D重建的新人工智能模型,它将2D视频剪辑转换为详细的3D结构——生成建筑物、雕塑和其他现实世界物体的逼真的虚拟复制品。
就像米开朗基罗从大理石块上雕刻出令人惊叹的、栩栩如生的视觉一样,Neuralangelo生成具有复杂细节和纹理的3D结构。然后,创意专业人士可以将这些3D对象导入设计应用程序,进一步编辑它们,用于艺术、视频游戏开发、机器人和工业数字双胞胎。
Neuralangelo将复杂材料的纹理(包括屋顶瓦片、玻璃窗格和光滑的大理石)从2D视频转换为3D资产的能力大大超过了之前的方法。高保真度使其3D重建更容易让开发人员和创意专业人士使用智能手机捕获的镜头为他们的项目快速创建可用的虚拟对象。
研究高级总监兼论文合著者Ming-Yu Liu说:“Neuralangelo提供的3D重建能力将给创作者带来巨大的好处,帮助他们在数字世界中重现现实世界。”“该工具最终将使开发人员能够将详细的物体——无论是小雕像还是大型建筑——导入视频游戏或工业数字双胞胎的虚拟环境中。”
在演示中,NVIDIA研究人员展示了该模型如何重现像米开朗基罗的大卫一样标志性物体,以及像平板卡车一样平凡的物体。Neuralangelo还可以重建建筑内部和外部——用NVIDIA湾区园区公园的详细3D模型进行演示。
视频地址:
https://www.youtube.com/watch?time_continue=55&v=PQMNCXR-WF8&embeds_referring_euri=https%3A%2F%2Fblogs.nvidia.com%2F&source_ve_path=Mjg2NjQsMjg2NjMsMTI3Mjk5LDEyNzI5OSwxMjcyOTksMjg2NjMsMTI3MzAxLDI4NjY2&feature=emb_logo
神经渲染模型在3D中看到
之前重建3D场景的人工智能模型一直在努力准确捕捉重复的纹理图案、同质的颜色和强烈的颜色变化。Neuralangelo采用即时神经图形原语,即NVIDIA Instant NeRF背后的技术,以帮助捕捉这些更精细的细节。
使用从不同角度拍摄的物体或场景的2D视频,模型选择几个捕捉不同观点的帧——就像艺术家从多个角度考虑一个主题以获得深度、大小和形状的感觉。
一旦确定了每帧的相机位置,Neuralangelo的人工智能就会创建一个粗糙的场景3D表示,就像雕塑家开始凿出拍摄对象的形状一样。
然后,模型优化渲染以锐化细节,就像雕塑家煞费苦心地凣石来模仿织物或人物的纹理一样。
最终结果是一个3D物体或大型场景,可用于虚拟现实应用程序、数字双胞胎或机器人开发。
在CVPR找到NVIDIA Research,6月18日至22日
Neuralangelo是NVIDIA Research将于6月18日至22日在温哥华举行的计算机视觉和模式识别会议(CVPR)上展示的近30个项目之一。这些论文涵盖的主题包括姿势估计、3D重建和视频生成。
其中一个项目,DiffCollage,是一种创建大规模内容的扩散方法——包括长景观方向、360度全景和循环运动图像。当输入具有标准宽高比的图像训练数据集时,DiffCollage将这些较小的图像视为较大视觉部分——就像拼贴画的碎片一样。这使得扩散模型能够生成具有凝聚力的大型内容,而无需在相同规模的图像上进行训练。
该技术还可以将文本提示转换为视频序列,使用捕获人类运动的预训练扩散模型进行演示

相关资讯:
https://shaderfun.com/2018/03/25/signed-distance-fields-part-2-solid-geometry/
相关文章







