
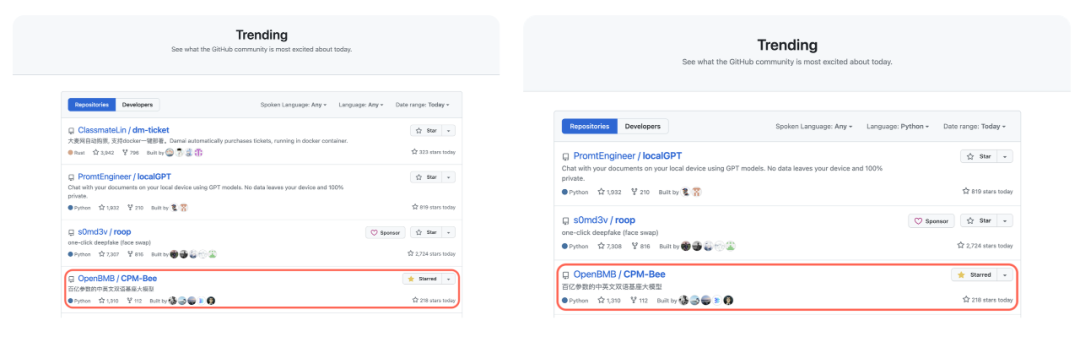
5月27日百亿参数中英双语基座模型 CPM-Bee 开源之后,在GitHub反响热烈,一度登上总榜第四、Python榜第三。
CPM-Bee 是一个基座模型,其开源的核心目的是更广泛地支持各种 NLP 应用场景,让大家可以自由地进行适配。我们在预训练的时候采用了一些特殊设计,所以它现在的输出比较稳定。如果在合适的数据上进行指令微调,CPM-Bee 会输出更高质量和有信息量的内容。


CPM-Bee 数据格式介绍
—
CPM-Bee 基座模型可以将多种自然语言处理任务统一用生成的方式解决。CPM-Bee 采用特殊的多任务预训练模式,所有的数据都统一用一个字典来管理。我们可以任意设计字典中的键值对来表达我们希望模型做的事情,同时预留一个<ans>字段,用于存储模型给出的答案。注意,<ans>字段是必需的,基本格式如下:
{"some_key": "...", "<ans>": ""}
尽管输入数据的格式是任意的,但由于模型在预训练阶段使用了有限的几种数据格式,我们建议您在使用 CPM-Bee 推理时尽量使用这些参考格式。
01 文本生成
# 文本生成-
{"input": "今天天气不错,", "prompt":"往后写100字", "<ans>":""}
prompt 字段用来给出一些提示和指定任务,该字段并不是必需的,但是我们建议您使用合理的 prompt 来更好地驱动模型。prompt 也可以被”hint”, “task”, “prompt”, “任务”, “提示”, “目标”, “target”等替换。请注意,prompt 一般会提供一些控制信息,如”往后写xxx字”,”中翻英”,”给这段话生成摘要”等。
02 翻译
# 翻译-
{"input": "今天天气不错,", "prompt":"中翻英", "<ans>":""}
CPM-Bee 目前支持中英互译。prompt 一般可选”中翻英”/”英翻中”,”中译英”/”英译中”,”把文章翻译为英文”/”把文章翻译为中文”,”Translate from English to Chinese”等。
03 问答
# 问答-
{"input": "今天天气不错,", "prompt":"问答", "question": "今天天气怎么样", "<ans>":""}
04 选择题
# 选择题-
{"input": "今天天气不错,", "prompt":"选择题", "question": "今天天气怎么样", "options": {"<option_0>": "好", "<option_1>": "坏"}, "<ans>":""}
options 可以等价替换为”answers”, “candidates”, “选项”…
05 命名实体识别
# NER-
{"input":"在司法部工作的小楠说,今天北京天气不错","<ans>":{"人名":"","地名":"","机构名": ""}}
以上是一些常见的任务的数据格式。请注意里面用到的字段不是严格限定的,您可以做一些近似语义的替换,比如把”中翻英”替换为”把这段话翻译成英文”。您也可以在微调时自由设计数据格式,例如,当您希望微调一个对话模型,您可以构造数据格式为
{"input": "用户:你好,我想问一下明天天气会怎样?\n<sep>AI:你好!明天的天气会根据你所在的城市而异,请告诉我你所在的城市。\n<sep>用户:我在北京。\n<sep>AI:", "<ans>": " 明天北京天气预计为阴转多云,最高气温26℃,最低气温18℃。"}
您也可以不使用<sep>,如下格式也可以:
{"input": "<问题>你好,我想问一下明天天气会怎样?\n<答案>你好!明天的天气会根据你所在的城市而异,请告诉我你所在的城市。\n<问题>我在北京。\n<答案>", "<ans>": " 明天北京天气预计为阴转多云,最高气温26℃,最低气温18℃。"}
CPM-Bee 微调流程
—
本教程将以一个序列-序列任务为例介绍对 CPM-Bee 基座模型的微调。这里我们选择的任务需要将一句白话文“翻译”成一句古诗。首先,微调需要准备原始数据,格式如下:
{"target": "3", "input": "[翻译]昏暗的灯熄灭了又被重新点亮。[0]渔灯灭复明[1]残灯灭又然[2]残灯暗复明[3]残灯灭又明[答案]"}
-
放置在路径 src/ccpm_example/raw_data/ 下 -
准备模型的 checkpoint,放在路径 src/ckpts/pytorch_model.bin 下,可在此链接下载权重:? https://huggingface.co/openbmb/cpm-bee-10b
进入工作路径:
cd src
运行 data_reformat.py 重新调整数据格式。注意,这里我们将原始数据转化为上述推荐的格式。在您的实验中,可以自行设置需要的格式并且编写自己的 data_reformat.py。
python data_reformat.py
{"input": "昏暗的灯熄灭了又被重新点亮。", "options": {"<option_0>": "渔灯灭复明", "<option_1>": "残灯灭又然", "<option_2>": "残灯暗复明", "<option_3>": "残灯灭又明"}, "question": "这段话形容了哪句诗的意境?", "<ans>": "<option_3>"}```
-
放置在路径 src/ccpm_example/bee_data/ 下
注:该格式为参考格式。微调时,您可以自由设计您的数据格式,可以不设置 prompt 字段,只要所提供的数据涵盖所有必要信息即可。但我们一般推荐将输入文本字段标识为 input/document/doc,如果您的任务可以被转化成选择题,则应当添加 options 字段与 question 字段;如果是一般的文本生成,包含 input+<ans> 即可。
构建二进制数据文件:
python preprocess_dataset.py --input ccpm_example/bee_data --output_path ccpm_example/bin_data --output_name ccpm_data
-
放在路径 ccpm_example/bin_data/ 下
注:应确保没有同名路径 ccpm_example/bin_data/,如存在同名路径,应先删除该路径再运行上述指令。如未提前删除,该指令会报错 ValueError: Dataset name exists,同时产生一个新路径 tmp/,此时应当连同 tmp/ 与同名路径 ccpm_example/bin_data/ 一并删除,之后再运行上述指令即可。
在模型微调脚本 scripts/finetune_cpm_bee.sh 中对超参数进行设置,我们对每一个超参数给出了注释:
#! /bin/bash# 四卡微调-
export CUDA_VISIBLE_DEVICES=0,1,2,3 -
GPUS_PER_NODE=4 -
NNODES=1 -
MASTER_ADDR="localhost" -
MASTER_PORT=12346 OPTS=""-
OPTS+=" --use-delta" # 使用增量微调(delta-tuning) -
OPTS+=" --model-config config/cpm-bee-10b.json" # 模型配置文件 -
OPTS+=" --dataset ccpm_example/bin_data/train" # 训练集路径 -
OPTS+=" --eval_dataset ccpm_example/bin_data/train" # 验证集路径 -
OPTS+=" --epoch 5" # 训练epoch数 -
OPTS+=" --batch-size 5" # 数据批次大小 -
OPTS+=" --train-iters 100" # 用于lr_schedular -
OPTS+=" --save-name cpm_bee_finetune" # 保存名称 -
OPTS+=" --max-length 2048" # 最大长度 -
OPTS+=" --save results/" # 保存路径 -
OPTS+=" --lr 0.0001" # 学习率 -
OPTS+=" --inspect-iters 100" # 每100个step进行一次检查(bmtrain inspect) -
OPTS+=" --warmup-iters 1". # 预热学习率的步数为1 -
OPTS+=" --eval-interval 50" # 每50步验证一次 -
OPTS+=" --early-stop-patience 5" # 如果验证集loss连续5次不降,停止微调 -
OPTS+=" --lr-decay-style noam" # 选择noam方式调度学习率 -
OPTS+=" --weight-decay 0.01" # 优化器权重衰减率为0.01 -
OPTS+=" --clip-grad 1.0" # 半精度训练的grad clip -
OPTS+=" --loss-scale 32768" # 半精度训练的loss scale -
OPTS+=" --start-step 0" # 用于加载lr_schedular的中间状态 -
OPTS+=" --load ckpts/pytorch_model.bin" # 模型参数文件 CMD="torchrun --nnodes=${NNODES} --nproc_per_node=${GPUS_PER_NODE} --rdzv_id=1 --rdzv_backend=c10d --rdzv_endpoint=${MASTER_ADDR}:${MASTER_PORT} finetune_cpm_bee.py ${OPTS}"echo ${CMD}$CMD
只需要运行脚本即可开始微调
bash scripts/finetune_cpm_bee.sh
以上是 CPM-Bee 的基础微调教程。我们也会持续完善更新 CPM-Bee 的文档信息,欢迎感兴趣的朋友继续关注和参与开源共建!
➤ 加社群/ 提建议/ 有疑问
请找 OpenBMB 万能小助手:



https://www.openbmb.org
长期开放招聘|含实习
开发岗 | 算法岗 | 产品岗
相关文章






