
Meta的MusicGen可以根据文本提示生成简短的新音乐,这些提示可以选择与现有旋律对齐。
与当今大多数语言模型一样,MusicGen基于Transformer模型。就像语言模型预测句子中的下一个字符一样,MusicGen预测音乐中的下一个部分。
研究人员使用Meta的EnCodec音频标记器将音频数据分解为更小的组件。作为一个并行处理令牌的单阶段模型,MusicGen快速高效。
该团队使用了20,000小时的许可音乐进行培训。特别是,他们依赖于10,000首高质量音乐曲目的内部数据集,以及来自Shutterstock和Pond5的音乐数据。
试玩地址:https://huggingface.co/spaces/facebook/MusicGen
-
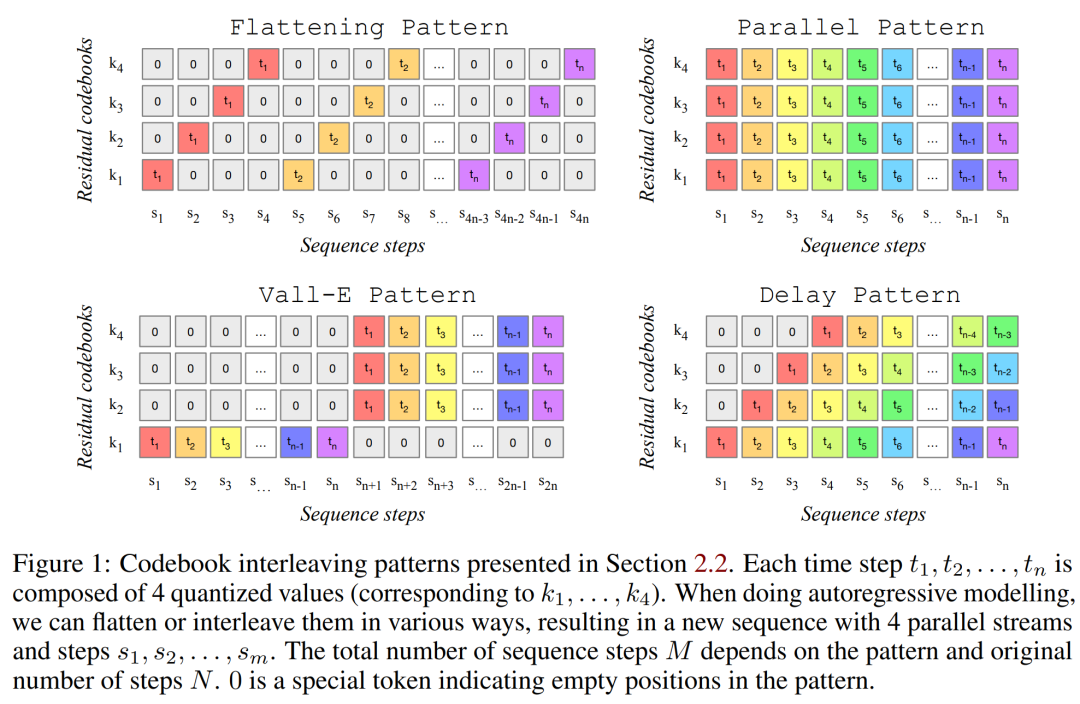
提出了一个简单高效的模型:可以在 32khz 产生高质量的音乐。MUSICGEN 可以通过有效的码本交错策略,用单阶段语言模型生成一致的音乐; -
提出一个单一的模型,进行文本和旋律条件生成,其生成的音频与提供的旋律是一致的,并符合文本条件信息; -
对所提出方法的关键设计选择进行了广泛的客观及人工评估。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






这是一个专注于人工智能产品的导航站。
