Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, Lidong Bing
[Alibaba Group]
Video-LLaMA:面向视频理解的指令微调音频-视觉语言模型
-
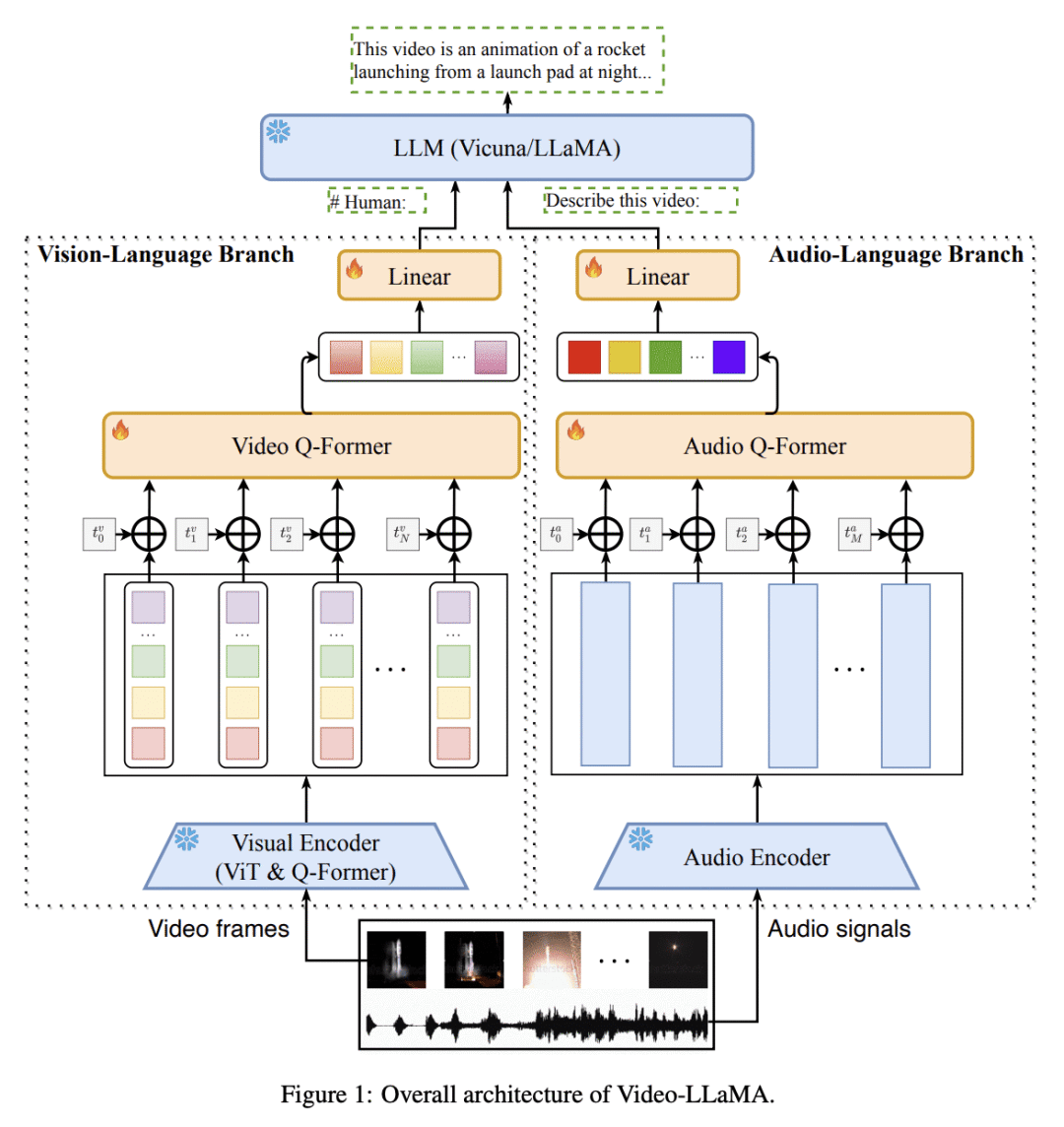
动机:为了赋予大型语言模型(LLM)理解视频中的视觉和听觉内容的能力,提出了一种新的多模态框架Video-LLaMA。与之前关注静态图像理解的视觉-LLM不同,Video-LLaMA解决了视频理解中的两个挑战:捕捉视觉场景的时序变化和集成音频-视觉信号。 -
方法:使用Video Q-former将预训练的图像编码器扩展为视频编码器,引入视频到文本生成任务学习视频和语言之间的对应关系。同时,利用预训练的音频编码器ImageBind,在一个共享的嵌入空间中对齐不同模态的输出。通过在大规模视觉描述数据集和大量视觉指令微调数据集上训练Video-LLaMA,使其能感知和理解视频内容。 -
优势:论文的主要优势是提出了Video-LLaMA框架,使得大型语言模型具备了理解视频内容的能力,并能生成与视频中的视听信息相关的有意义的回应。这突显了Video-LLaMA作为有潜力的音视频AI助手的潜力。
本文提出了Video-LLaMA,一种多模态框架,通过连接语言解码器和预训练的单模态模型,实现了人机之间基于视频的对话,为大型语言模型赋予了视频理解能力。
https://arxiv.org/abs/2306.02858

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






这是一个专注于人工智能产品的导航站。
