MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models
M Monajatipoor, L H Li, M Rouhsedaghat, L F. Yang, K Chang
[UCLA & USC]
MetaVL: 将上下文学习能力从语言模型迁移到视觉-语言模型
-
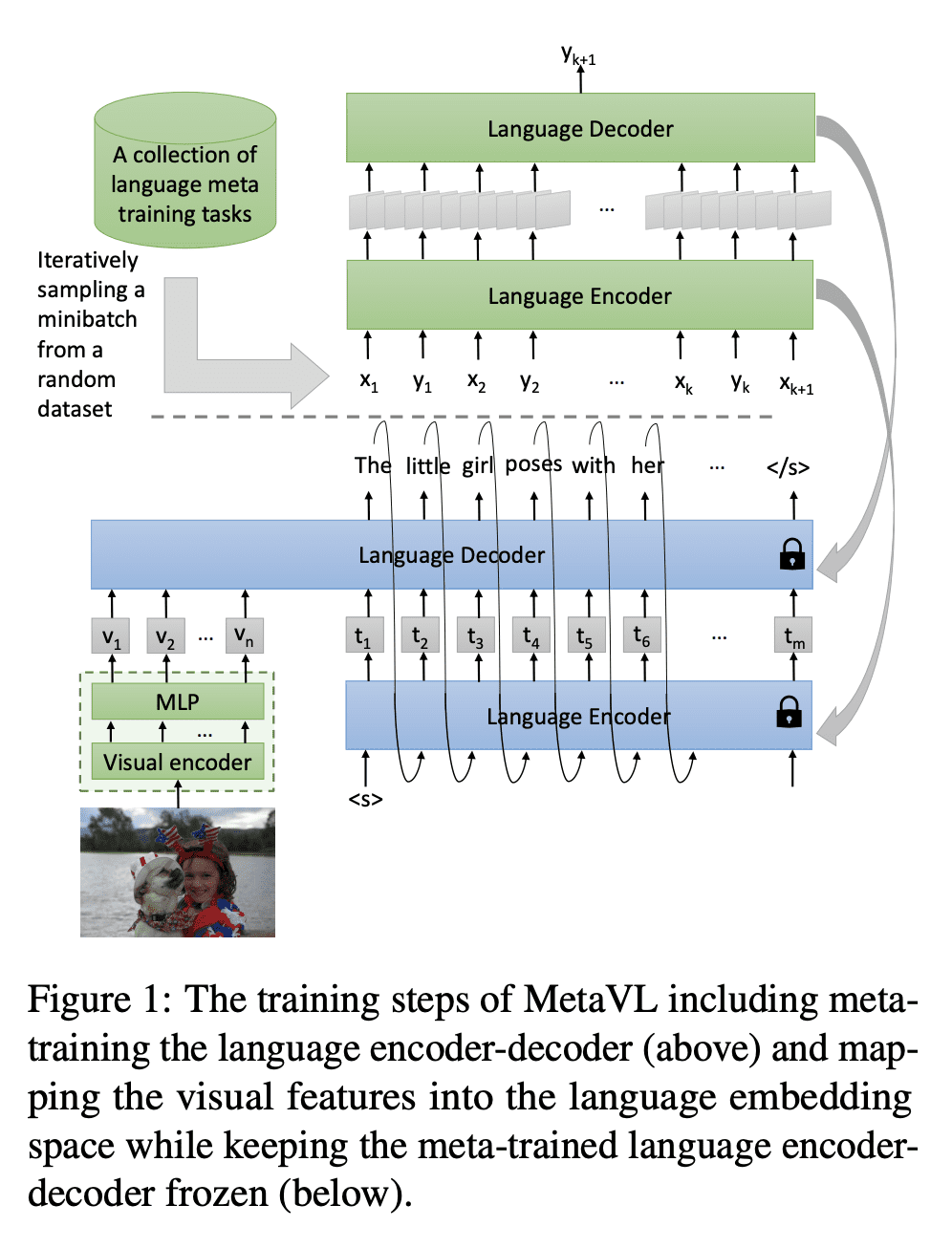
动机:研究如何在视觉-语言领域实现上下文学习,将单模态的元学习知识转移到多模态中,以提高大规模预训练视觉-语言(VL)模型的能力。 -
方法:首先在自然语言处理(NLP)任务上元训练一个语言模型,实现上下文学习,然后通过连接一个视觉编码器将该模型转移到视觉-语言任务上,以实现跨模态的上下文学习能力的转移。 -
优势:实验证明,跨模态的上下文学习能力可以转移,该模型显著提高了视觉-语言任务上的上下文学习能力,并且在模型大小方面能够有显著的优化,例如在VQA、OK-VQA和GQA上,所提出方法在参数数量减少约20倍的情况下超过了基准模型。
探索了将元学习的上下文学习能力从单模态迁移到多模态的可能性,证明了在视觉-语言任务中通过迁移可以显著提升上下文学习能力,甚至在模型大小方面实现优化。
https://arxiv.org/abs/2306.01311
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...







这是一个专注于人工智能产品的导航站。
