Machine Intelligence Research
阿里巴巴集团国际部和苏黎世联邦理工学院的研究人员合作提出了MVLT模型,这是一种基于掩码的视觉-语言Transformer模型,用于时尚领域中的跨模态表征学习。该模型使用基于视觉Transformer模型对BERT进行了重构,成为时尚领域中第一个可端到端训练的多模态框架。为了更好地理解时尚商品,本文还引入了掩码图像重建(Masked Image Reconstruction, MIR)预训练策略。MVLT模型易于使用,且扩展性强,能够接收原始多模态数据作为输入,对视觉-语言模态进行隐式的对齐,而无需引入额外的预处理模型(例如: ResNet)。此外,MVLT模型可轻松泛化到各种匹配式任务和生成式任务中。实验结果表明,在检索任务的rank@5指标和识别任务的精度指标上,MVLT模型表现比Fashion-Gen 2018数据集获胜者Kaleido-BERT提高了17%和3%。全文已发表于MIR 2023年第3期中,可免费下载。
代码已开源在:
https://github.com/gewelsji/mvlt


图片来自Springer
全文下载:
Masked Vision-language Transformer in Fashion
Ge-Peng Ji, Mingchen Zhuge, Dehong Gao, Deng-Ping Fan, Christos Sakaridis & Luc Van Gool
https://link.springer.com/article/10.1007/s11633-022-1394-4
ETH CVL实验室更多优质成果:
https://www.trace.ethz.ch/publications.html
Transformer模型的出现引起了学术界的广泛关注,并促进了计算机视觉(CV)和自然语言处理(NLP)领域的发展。由于Transformer模型的卓越表现,研究者们也不断探索其在视觉-语言(VL)领域的作用。为更好地利用 CV 和 NLP 领域中的预训练模型,现有的通用视觉-语言模型主要使用预训练后的BERT模型、视觉特征提取器或者同时使用两者。然而,通用的视觉-语言方法仍难以被应用于电商中的时尚领域,主要因为以下两个问题:(a)特征粒度不足:不同于具有复杂背景的通用场景,若模型仅关注时尚产品的粗粒度语义是远远不足的,因为这种方式将导致网络收敛于次优解。反之,面向时尚领域的模型往往需要更细粒度的表征,例如:一件具有不同材质(例如:羊毛、亚麻、棉)或衣领(例如:立领、古巴领、温莎领)的西装。(b)迁移能力差:就时尚领域任务而言,当前预提取的视觉特征缺乏针对性,从而限制了跨模态表征的能力。
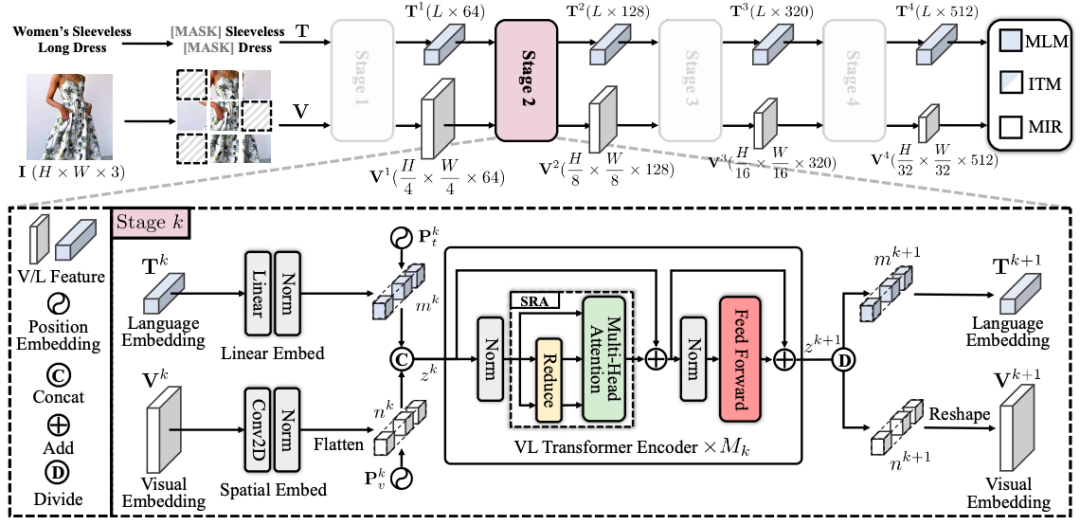
图1: MVLT的框架示意图。该模型的整体结构由四个阶段组成,每个阶段均包含语言和视觉嵌入过程以及M_k个Transformer编码器。通过在三个子任务中引入掩码策略,即:掩码图像重建(MIR)、图像-文本匹配(ITM)和掩码语言建模(MLM),MVLT以端到端的方式进行训练。详细描述请参见原文第三章节。
为了解决上述问题,本文提出了一个新颖的视觉-语言多模态框架(参见图1),名为掩码视觉-语言Transformer (Masked Vision-Language Transformer, MVLT)。本文首先针对时尚领域的VL框架引入了一个生成式任务,即:掩码图像重建(Masked Image Reconstruction,MIR)。相比于之前的预训练任务,例如:掩码图像建模(回归任务)或者掩码图像分类(分类任务),MIR使网络通过像素级视觉信息习得更多细粒度表征(请参见图2)。此外,受金字塔视觉Transformer模型PVT的启发,本方法使用金字塔结构作为视觉-语言Transformer。所引入的MIR任务显著增强了模型对特定时尚领域理解和生成式任务的适应能力,并且能够以端到端的方式训练。为此,MVLT模型可直接处理原始的稠密形式的多模态输入,即:语言词例(token)和图像块(patch),而无需额外的预处理模型,如使用ResNet作为视觉特征提取器。
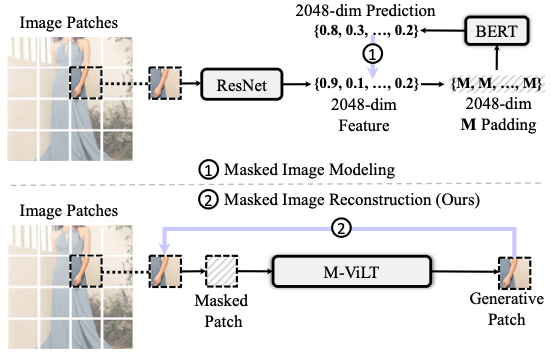 图2: 用于视觉-语言预训练的视觉重建任务使用了随机掩码策略(即: 使用M填充去替换原始向量)的掩码图像建模(上图),其用于在特征层级重建预提取的视觉语义(向量)。本文引入基于掩码图像重建的生成式任务(下图),其直接重建像素层级的原始图像。
图2: 用于视觉-语言预训练的视觉重建任务使用了随机掩码策略(即: 使用M填充去替换原始向量)的掩码图像建模(上图),其用于在特征层级重建预提取的视觉语义(向量)。本文引入基于掩码图像重建的生成式任务(下图),其直接重建像素层级的原始图像。
● 本文提出一种全新的掩码图像重建(MIR)任务,这是在时尚领域视觉-语言预训练中第一个采用像素级生成式的方案。
● 基于MIR任务,本文提出了一个用于时尚领域的端到端视觉-语言框架MVLT,极大提高了下游任务和大规模网站应用的可迁移性。
● 广泛实验表明,MVLT模型在匹配式和生成式任务上的表现均明显优于同期的前沿模型。
全文下载:
Masked Vision-language Transformer in Fashion
Ge-Peng Ji, Mingchen Zhuge, Dehong Gao, Deng-Ping Fan, Christos Sakaridis & Luc Van Gool
https://link.springer.com/article/10.1007/s11633-022-1394-4
ETH CVL实验室更多优质成果:
https://www.trace.ethz.ch/publications.html
【本文作者】

MIR为所有读者提供免费寄送纸刊服务,如您对本篇文章感兴趣,请点击下方链接填写收件地址,编辑部将尽快为您免费寄送纸版全文!
说明:如遇特殊原因无法寄达的,将推迟邮寄时间,咨询电话010-82544737
收件信息登记:
https://www.wjx.cn/vm/eIyIAAI.aspx#
关于Machine Intelligence Research
Machine Intelligence Research(简称MIR,原刊名International Journal of Automation and Computing)由中国科学院自动化研究所主办,于2022年正式出版。MIR立足国内、面向全球,着眼于服务国家战略需求,刊发机器智能领域最新原创研究性论文、综述、评论等,全面报道国际机器智能领域的基础理论和前沿创新研究成果,促进国际学术交流与学科发展,服务国家人工智能科技进步。期刊入选”中国科技期刊卓越行动计划”,已被ESCI、EI、Scopus、中国科技核心期刊、CSCD等数据库收录。

相关文章
