Meta官网博客更新:人工智能研究人员在语音生成人工智能方面取得了突破。我们开发了Voicebox,这是第一个可以推广到语音生成任务的模型,它没有经过专门训练,以最先进的性能来完成。

与图像和文本的生成系统一样,Voicebox以各种风格创建输出,它可以从头开始创建输出,也可以修改给出的样本。但是,Voicebox不是创建图片或文本段落,而是生成高质量的音频剪辑。该模型可以跨六种语言合成语音,以及执行降噪、内容编辑、样式转换和多样化的样本生成。
论文地址:https://research.facebook.com/file/649409006862002/paper_fixed.pdf
Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, Wei-Ning Hsu

在Voicebox之前,生成语音人工智能需要使用精心准备的训练数据对每项任务进行特定培训。Voicebox使用一种新方法,仅从原始音频和随附的转录中学习。与音频生成的自动回归模型不同,Voicebox可以修改给定样本的任何部分,而不仅仅是给定音频剪辑的结尾。
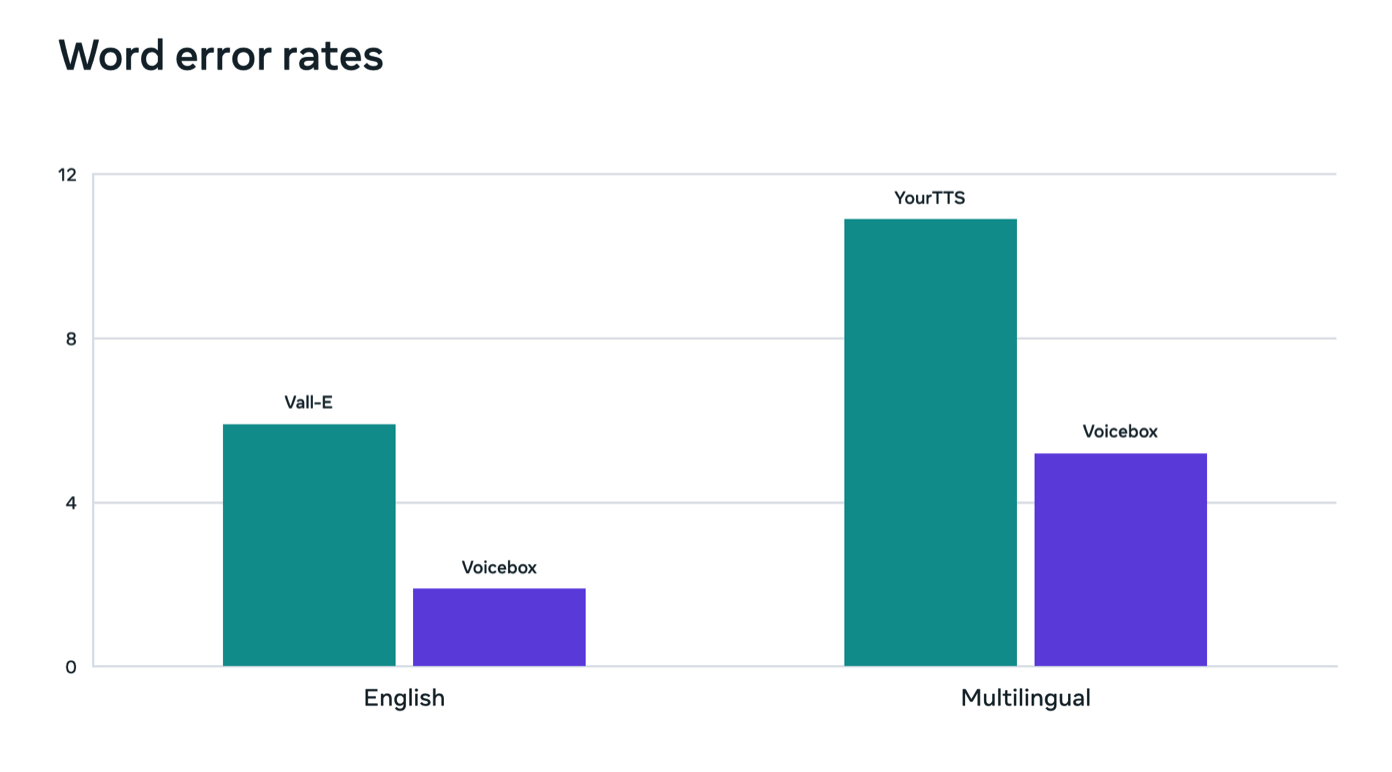
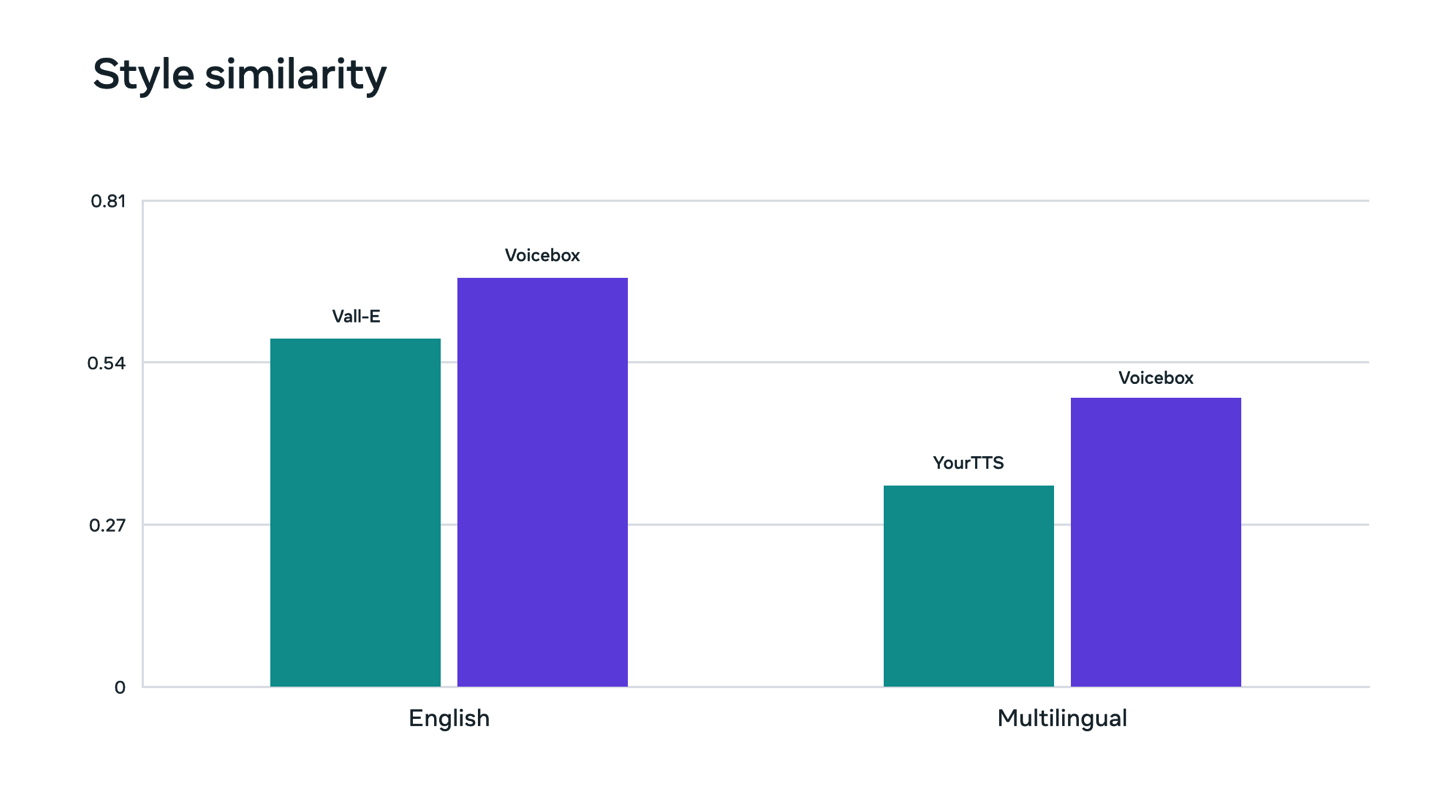
Voicebox基于一种名为Flow Matching的方法,该方法已被证明可以改进扩散模型。Voicebox在零拍摄文本转语音方面优于当前最先进的英语模型VALL-E,在可理解性(5.9%对1.9%的单词错误率)和音频相似性(0.580对0.681)方面,同时速度高达20倍。对于跨语言风格的传输,Voicebox的性能优于YourTTS,将平均单词错误率从10.9%降低到5.2%,并将音频相似性从0.335提高到0.481。
语音生成的新方法
现有语音合成器的主要局限性之一是,它们只能根据专门为该任务准备的数据进行训练。这些输入——被称为单调、干净的数据——很难产生,因此它们只存在于有限的数量上,它们导致听起来单调的输出。
我们在流匹配模型上构建了Voicebox,这是Meta在非自回归生成模型上的最新进展,该模型可以学习文本和语音之间的高度非确定性映射。非确定性映射很有用,因为它使Voicebox能够从不同的语音数据中学习,而无需仔细标记这些变体。这意味着Voicebox可以在更多样化的数据和更大规模的数据上进行训练。
我们用英语、法语、西班牙语、德语、波兰语和葡萄牙语的公共领域有声读物录制了超过5万小时的演讲和成绩单。Voicebox经过训练,在给定周围的演讲和该段的成绩单时预测演讲段。在学会了从上下文填充语音后,该模型可以将其应用于语音生成任务,包括在音频录制中间生成部分,而无需重新创建整个输入。
这种多功能性使Voicebox能够在各种任务中执行良好,包括:
上下文文本到语音合成:使用长度仅两秒钟的输入音频样本,Voicebox可以匹配样本的音频样式,并将其用于文本到语音生成。未来的项目可以利用这种能力,为不会说话的人带来演讲,或者允许人们自定义非玩家角色和虚拟助理使用的声音。
跨语言风格转换:给定英语、法语、德语、西班牙语、波兰语或葡萄牙语的语音样本和一段文本,Voicebox可以读取该语言的文本。这种能力令人兴奋,因为在未来,它可用于帮助人们以自然、真实的方式进行交流——即使他们不会说相同的语言。
语音去噪和编辑:Voicebox的上下文学习使其擅长生成语音以无缝编辑录音中的片段。它可以重新合成被短期噪音损坏的演讲部分,或者替换说错的单词,而无需重新录制整个演讲。一个人可以识别语音的哪个原始部分被噪音损坏(如狗叫),裁剪它,并指示模型重新生成该部分。有一天,这项功能可以用来清理和编辑音频,就像流行的图像编辑工具调整照片一样简单。
多样化的语音采样:从多样化的野外数据中学习后,Voicebox可以生成更能代表人们在现实世界和上述六种语言中说话的语音。将来,这种能力可用于生成合成数据,以帮助更好地训练语音助理模型。我们的结果显示,在Voicebox生成的合成语音上训练的语音识别模型的性能几乎与在真实语音上训练的模型一样好,错误率下降了1%,而以前文本到语音模型的合成语音的误差率下降了45%至70%。
负责任地分享生成性人工智能研究
Voicebox代表了生成人工智能研究向前迈出的重要一步。其他具有任务概括功能的可扩展生成人工智能模型在文本、图像和视频生成方面引发了对跨任务潜在应用的兴奋。我们希望将来看到对演讲的类似影响。我们期待着继续在音频领域进行探索,并看到其他研究人员如何利用我们的工作。






