DeepKE-LLM链接:
https://github.com/zjunlp/DeepKE/tree/main/example/llm
OpenKG地址:
http://openkg.cn/tool/deepke
Gitee地址:
https://gitee.com/openkg/deepke/tree/main/example/llm
开放许可协议:Apache-2.0 license
贡献者:浙江大学(张宁豫、张锦添、王潇寒、桂鸿浩、姜一诺、陈华钧)
1、背景
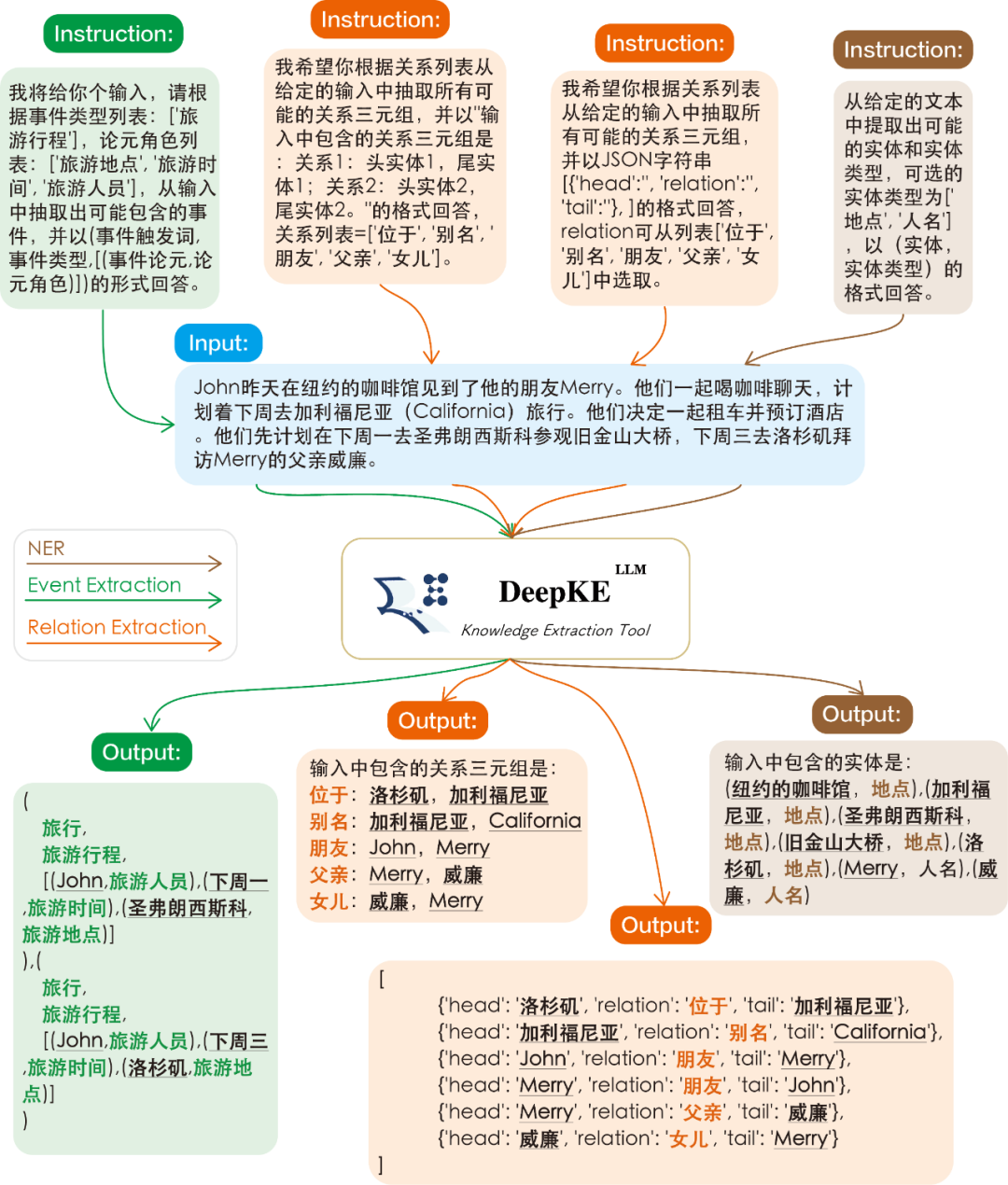
2、支持多种大模型
DeepKE-LLM目前支持多个大模型如Llama系列模型(Alpaca、Linly等)、ChatGLM等(MOSS、CPM-Bee、Falcon开发测试中将于近期支持),并通过自研的EasyInstruct支持调用OpenAI和Claude的系列模型,还进行了多实例并发请求(BatchPrompt)优化。此外,DeepKE-LLM提供了丰富的提示(Prompt)形式,含文本指令、代码提示(Code Prompt)等,以满足不同场景下知识抽取的需求。
首先执行以下脚本安装python依赖包。
>> conda create -n deepke-llm python=3.9
>> conda activate deepke-llm
>> cd example/llm
>> pip install -r requirements.txt
大模型时代, DeepKE-LLM采用全新的环境依赖
注意!!是example/llm文件夹下的requirements.txt。
>> python examples/generate_lora.py --load_8bit --base_model ./zhixi --lora_weights ./lora --run_ie_cases
>> CUDA_VISIBLE_DEVICES="0" python inference_llama.py \
--base_model '智析大模型相对路径' \
--lora_weights '智析大模型Lora权重相对路径' \
--input_file '输入文件相对路径' \
--output_file '输出文件相对路径' \
--load_8bit \
下图对比了通过DeepKE-LLM使用智析大模型和ChatGPT的中英双语知识抽取效果。可以发现其取得了较为准确和完备的抽取效果。此外,我们也发现智析仍会出现一些抽取错误,我们会在未来继续增强底座模型的中英文语义理解能力并引入更多高质量的指令数据以提升模型性能。

DeepKE-LLM还支持多种大模型如Llama系列、ChatGLM等的微调。依照文档的说明,下载完毕数据和模型后,可通过下列脚本即可完成抽取大模型的指令微调训练(基于Llama-7B的Lora微调),我们还提供了多机多卡训练脚本供用户使用。
>> CUDA_VISIBLE_DEVICES="0" python finetune_llama.py \
--base_model '大模型相对路径' \
--train_path '训练数据相对路径' \
--output_dir '输出模型相对路径' \
--batch_size 128 \
--micro_train_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 1000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]' \
--train_on_inputs \
--group_by_length \
2.3 使用 GPT、Anthropic系列模型
通过pip install easyinstruct安装EasyInstruct包,根据LLMICL中文档配置好数据集和API Key等参数后,直接运行python run.py文件即可。
其他模型的使用烦请查阅DeepKE-LLM的README文档。
3、抽取大模型训练
智析大模型基于LLaMA(13B)进行了全量预训练,并基于知识图谱转换指令(KG2Instructions,如下图)技术产生的大量指令数据来提高语言模型对于人类抽取指令的理解。
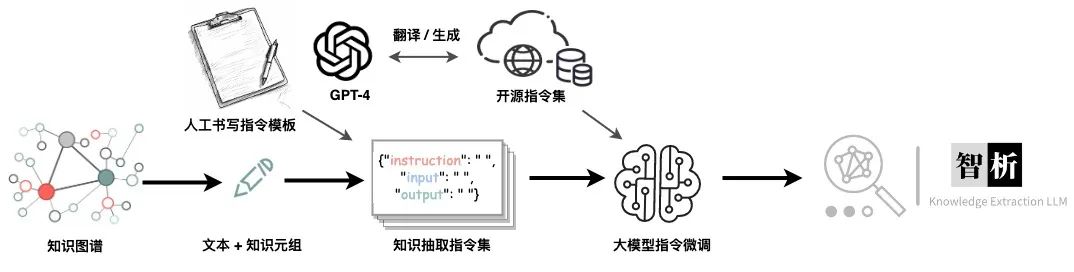
为了在保留原来的代码能力和英语能力的前提下,来提升模型对于中文的理解能力,我们并没有对词表进行扩增,而是搜集了中文语料、英文语料和代码语料。其中中文语料来自于百度百科、悟道和中文维基百科;英文语料是从LLaMA原始的英文语料中进行采样,同时扩充了英文维基数据(原始论文中的英文维基数据的最新时间点是2022年8月,我们额外爬取了2022年9月到2023年2月,共六个月的数据)。对上面爬取到的数据集,我们使用了启发式的方法,剔除了数据集中有害的内容和重复的数据。最后我们使用5500K条中文样本、1500K条英文样本、900K条代码样本基于transformers的trainer搭配Deepspeed ZeRO3进行预训练。
接着,我们构建了针对抽取加强的指令微调数据集以提升模型的知识抽取能力,主要采取的是基于知识图谱转换指令(KG2Instructions)技术。我们基于维基百科和WikiData知识图谱,通过远程监督、Schema约束过滤等方法构建大量的指令数据,并通过随机采样人工指令模板的方式提升指令的泛化性。此外,我们还使用大量开源中英文学术抽取数据集构建指令微调数据集。
除了知识抽取能力之外,智析大模型也继承了基座模型的通用指令遵循能力如翻译、理解、代码、创作和推理等能力,详情烦请查阅KnowLM(https://github.com/zjunlp/KnowLM)的文档。
4、小结和展望
致谢:感谢多年来对DeepKE项目提供支持的同学(部分同学已毕业)、老师和朋友(排名不分先后):余海阳、陶联宽、徐欣、乔硕斐、毛盛宇、黎洲波、李磊、欧翌昕、王鹏、习泽坤、方润楠、陈想、毕祯、陈静、梁孝转、李欣荣、黄睿、翁晓龙、徐子文、张文、郑国轴、张珍茹、谭传奇、陈强、熊飞宇、黄非等。
相关文章






