
最近,UltraLM-13B 在斯坦福大学 Alpaca-Eval 榜单中位列 开源模型榜首,是 唯一一个得分在 80 以上的开源模型。
ChatGPT 之后,开源社区内复现追赶 ChatGPT 的工作成为了整个领域最热的研究点。其中,对齐(Alignment)技术是最重要的环节之一,来自斯坦福大学、伯克利、微软、Meta、Stability.AI 等多个机构都争相推出相关的模型和方法(如Alpaca、Vicuna、WizardLM 等等)。
我们在探索对齐技术的过程中发现,训练出具有基本指令理解和追随能力的模型本身难度不高,但训练出可以针对各类指令都能给出高质量、有信息量和逻辑性回复的模型则十分困难。团队通过可扩展多样性(Scalable Diverse)的方法来大规模构造指令数据 UltraChat,并且在此之上开发了 UltraLM 对话语言模型。
斯坦福 Alpaca Eval 榜单介绍
—
AlpacaEval 是斯坦福大学发布的用于自动评估大语言模型的排行榜,它包括了从测评数据集、模型回答生成,到自动评估的完整评测流程,目前榜单已经包含了来自全球各个机构的多个代表性模型。具体而言,该排行榜主要评估大模型遵从指令的能力以及回答质量,其中排行榜所使用的数据集共计805条指令,集成了来自于 Self-instruct,Open Assistant, Vicuna 等项目发布的测评数据。排行榜的具体指标计算方式为使用GPT-4自动评估当前模型的回答与 Text-Davinci-003 的回答,统计当前模型的胜率。
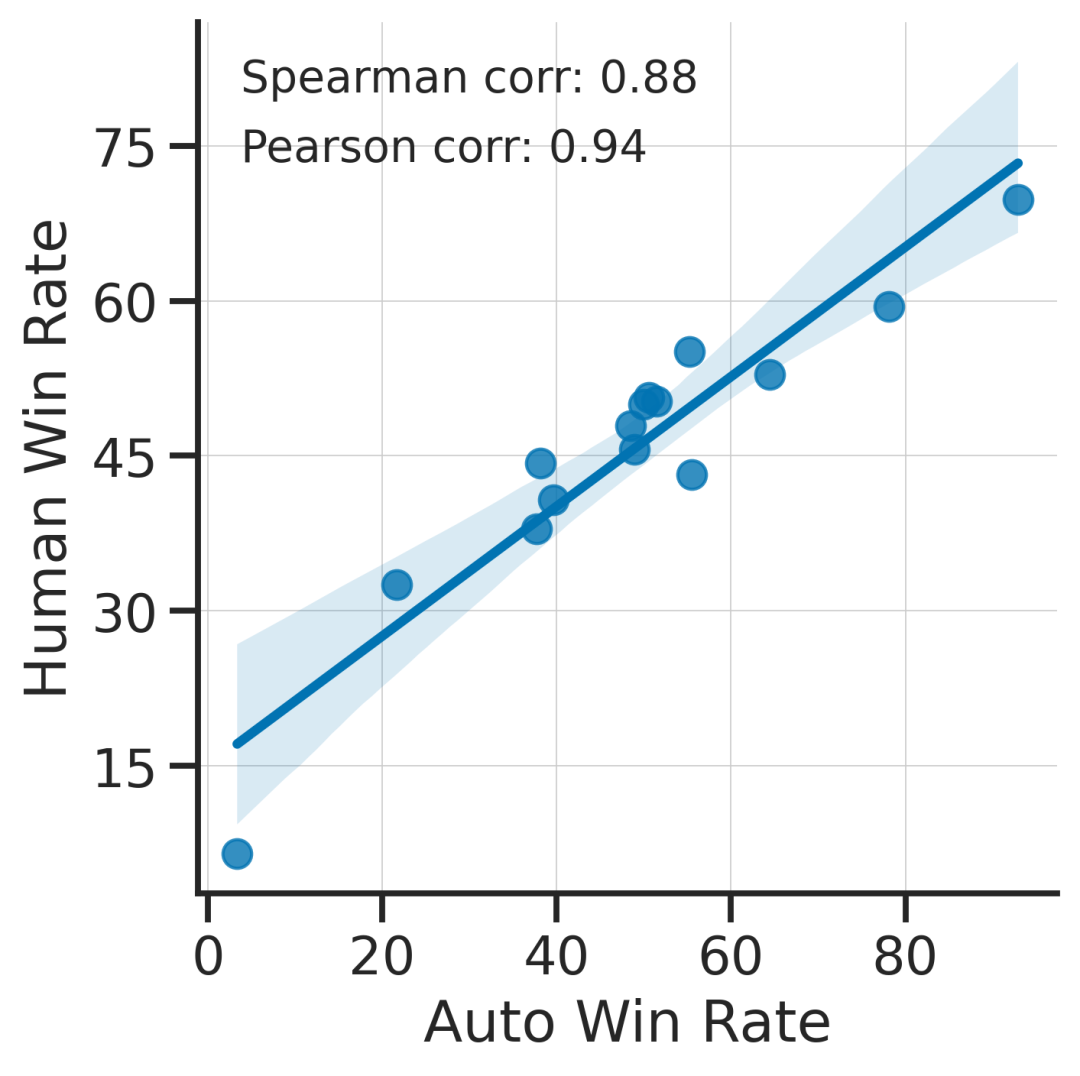
Alpaca Eval自动化评测和人类专家高度吻合
榜单情况
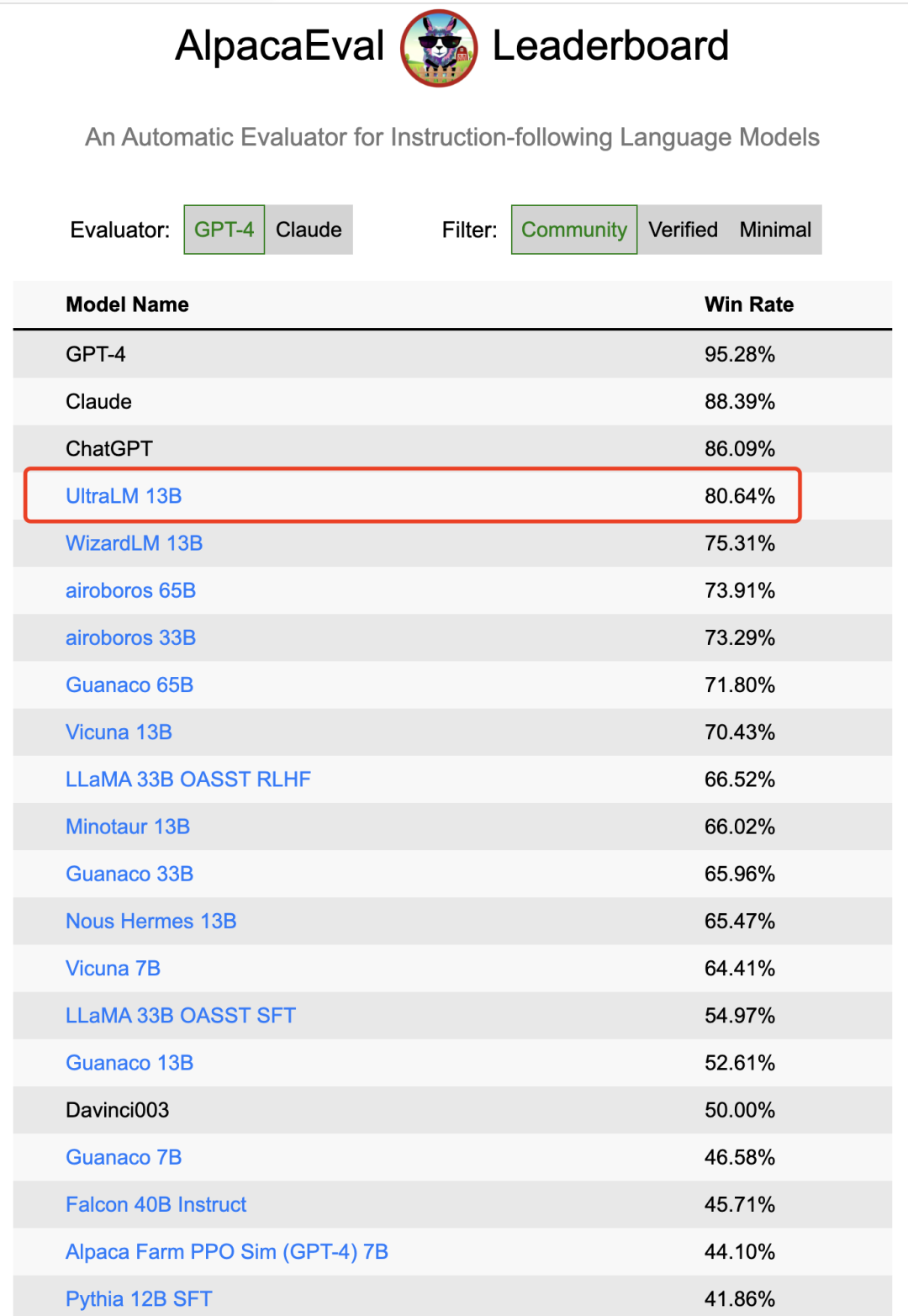

斯坦福大学Alpaca Eval榜单情况
关于 UltraLM 和 UltraChat
—
UltraLM-13B 是一个在 UltraChat 数据上训练而来的大语言模型,它具有丰富的世界知识和超强的指令理解和跟随能力,能对各类问题/指令给出很有信息量的回复。
作为UltraLM的能力来源,UltraChat 由清华大学、面壁智能、知乎等机构在 OpenBMB 开源社区构建,这是一个大规模、高质量、高度多样化的多轮指令数据,包含了 150余万条 多轮指令数据。
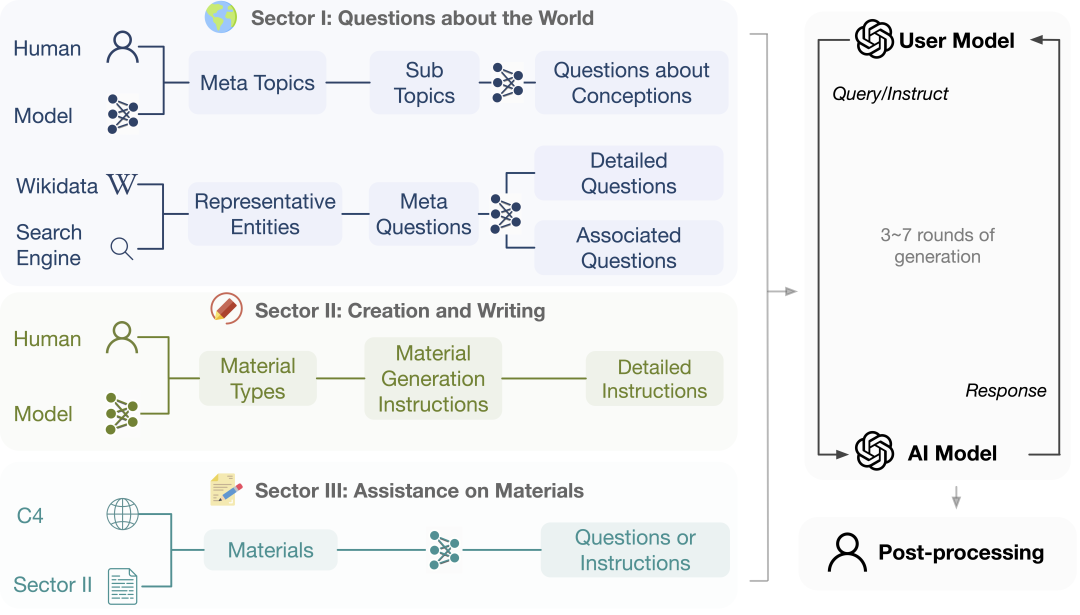
UltraChat秉承“可扩展多样化(Scalable Diverse)”的原则,即 并非通过少量样本的选取来达到多样化的目的,而是设计方法论使得多样化数据可以大规模扩展。UltraChat设计了三个模块来涵盖人类与机器可能交互的范式:信息获取、条件信息创造、信息转换,并且对用户模型进行了个性化建模。
在我们的文本多样化统计(Lexical Diversity)中,UltraChat 在 150 万条数据规模的情况下达到了 74.3 的得分,而此前公开数据的多样性得分最高仅有 67.1。

UltraChat数据分布
UltraLM 直接采用监督指令微调的方式对 LLaMA 进行全参数微调。对于 UltraChat 中的每一组多轮对话,将其分割成长度不超过 2048 的片段,遮蔽模型回答部分并计算该部分损失进行训练。该训练方式使得模型能够获得当前用户输入及对话历史作为上下文进行生成,有效保证了多轮对话的连贯性。
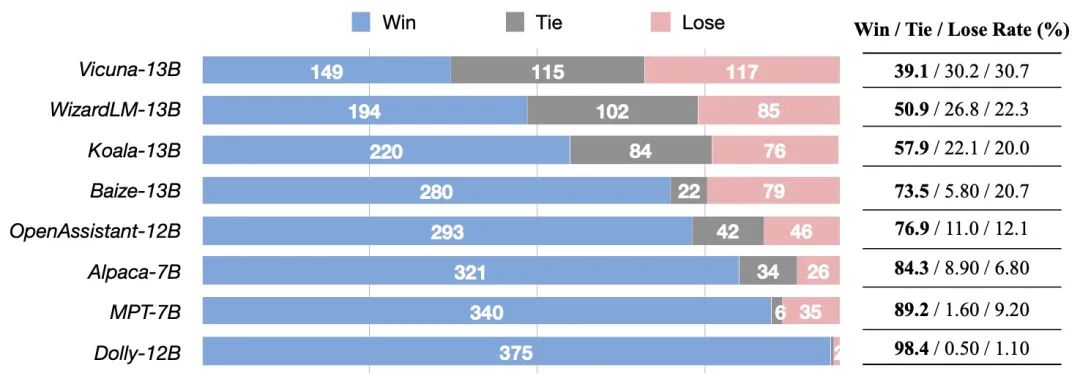
UltraLM与其他模型的对比评测
在上述的测试中,UltraLM 与其他模型都使用了各自的定制化系统提示来增强模型回复的质量。团队发现,尽管 UltraLM 在训练过程中并未使用系统提示,在测试过程中系统提示对于模型回复质量的提升仍有重要作用。
尽管 UltraLM 在评测中领先其他开源模型,可以对多种形式的指令和问题给出符合人类价值观且有信息量的回复,但它仍然具有幻觉等大模型常有问题,我们期待与 OpenBMB 开源社区的朋友们一起推动大模型对齐技术的发展,继续推出更加强大的模型。
➤ 加社群/ 提建议/ 有疑问
请找 OpenBMB 万能小助手:


https://www.openbmb.org
长期开放招聘|含实习
开发岗 | 算法岗 | 产品岗
相关文章






