Guiding Image Captioning Models Toward More Specific Captions
Simon Kornblith, Lala Li, Zirui Wang, Thao Nguyen
[Google DeepMind & Apple AI/ML & University of Washington]
指导图像描述模型生成更具体的描述
-
动机:图像描述生成通常被定义为为图像生成与参考图像描述对的分布匹配的字幕的任务。然而,标准描述数据集中的参考描述往往较短,可能无法唯一地描述图像。这些问题在直接从互联网收集的图像-替代文本对上训练模型时进一步加剧。本文展示了可以通过对训练过程进行最小的改变来生成更具体的描述。 -
方法:通过对自回归描述模型进行微调,实现了无分类器的引导,以估计描述的条件和无条件分布。在解码时应用的引导规模控制了在最大化p(描述|图像)和p(图像|描述)之间的权衡。进一步探索了使用语言模型来引导解码过程,从无分类器引导的参考自由与参考基础描述度量的帕累托前沿获得了小的改进,并显著提高了仅从最小策划的网络数据训练的模型生成的描述的质量。 -
优势:与标准的贪婪解码相比,解码时引导规模为2倍可以显著提高无参考度量,如CLIPScore (0.808 vs. 0.775) 和CLIP嵌入空间中的描述→图像检索性能 (recall@1 44.6% vs. 26.5%),但会降低标准的基于参考的描述度量 (例如,CIDEr 78.6 vs 126.1)。
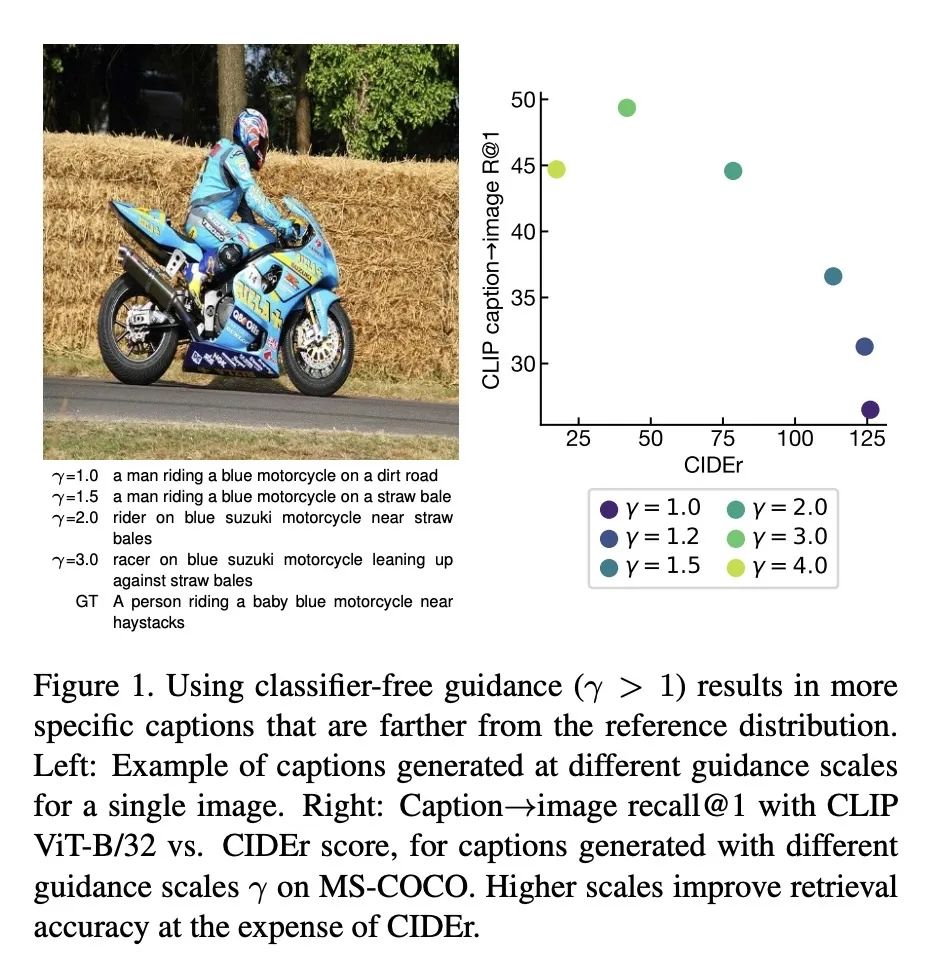
提出两种策略来引导图像描述模型生成更具体的描述:无分类器引导和语言模型引导,并展示了无分类器引导可以产生更接近对应图像的描述,但离人类提供的参考描述更远。
https://arxiv.org/abs/2307.16686
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
这是一个专注于人工智能产品的导航站。
