Studying Large Language Model Generalization with Influence Functions
Roger Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, Evan Hubinger, Kamilė Lukošiūtė, Karina Nguyen, Nicholas Joseph, Sam McCandlish, Jared Kaplan, Samuel R. Bowman
[Anthropic]
基于影响函数的大型语言模型泛化研究
-
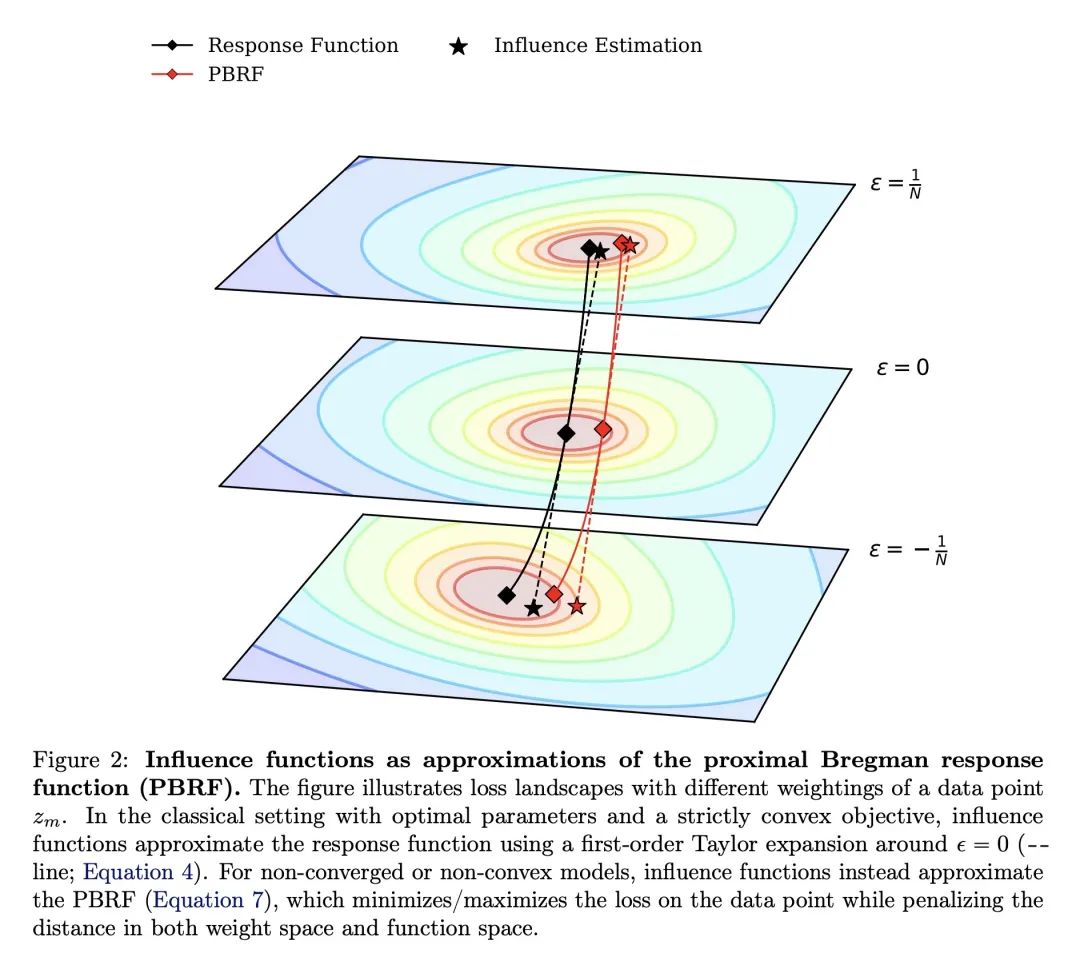
动机:为了更好地理解机器学习模型并减少相关风险,研究者希望找出哪些训练样本对给定行为的贡献最大。影响函数旨在回答一个反事实问题:如果将给定序列添加到训练集中,模型的参数(及其输出)会如何变化?
-
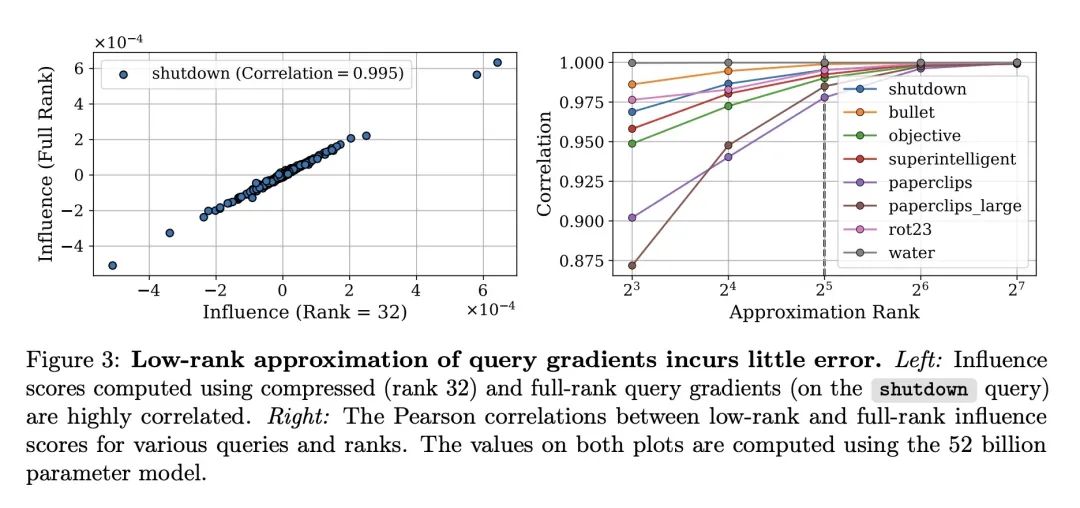
方法:使用Eigenvalue-corrected Kronecker-Factored Approximate Curvature(EK-FAC)近似来扩展到大型语言模型(LLM)。此外,研究了两种算法技术来减少计算候选训练序列梯度的成本:TF-IDF过滤和查询批处理。
-
优势:EK-FAC在IHVP计算上比传统的影响函数估计器快数个数量级,但达到了相似的准确性。此外,影响函数为我们提供了一个强大的新工具,用于研究LLMs的泛化特性。
通过使用EK-FAC近似和其他技术,本文成功地将影响函数扩展到大型语言模型,揭示了模型的泛化模式和训练数据之间的关系。
https://arxiv.org/abs/2308.03296 
相关文章
