神经网络的推理代码通常是使用 Python 语言编写的。但是相比于Python,C/C++ 代码运行速度更快,因此一些开发者尝试用 C/C++ 语言实现神经网络,Georgi Gerganov 是其中一位佼佼者,他构建的开源项目 llama.cpp,让开发者在没有 GPU 的条件下也能运行 Meta 的 Llama 模型,甚至在 MacBook 和树莓派上也可以运行 Llama,让没有高级GPU的开发者都能在家动手把玩大模型。
那么,llama.cpp 有何优势呢?
- 无需任何额外依赖,相比 Python 代码对 PyTorch 等库的要求,C/C++ 直接编译出可执行文件,跳过不同硬件的繁杂准备;
- 支持 Apple Silicon 芯片的 ARM NEON 加速;
- 具有 F16 和 F32 的混合精度;
- 支持 4-bit 量化;
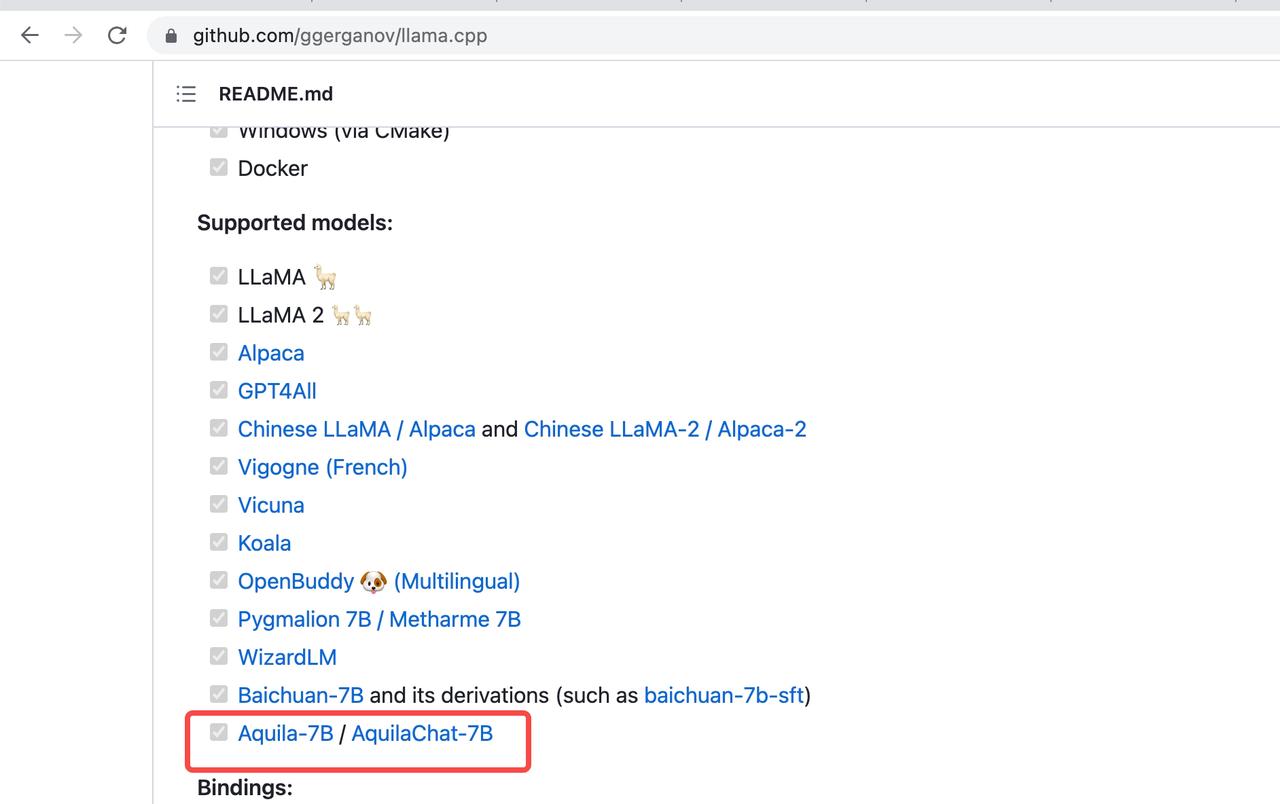
现在,悟道·天鹰Aquila已兼容 llama.cpp。大家可以用llama.cpp享受 Aquila系列模型的极速推理。实测可以在苹果电脑 M1 芯片上跑起来~
值得注意的是,Aquila与Llama结构不同,其tokenizer基于BPE格式,为此我们在llama.cpp增加vocabtype新特性(PR#2487 已被 llama.cpp 官方合并),大家在使用 llama.cpp加速 Aquila推理时,指定bpe即可,无需更多改动。

下面快来看看具体操作步骤吧!
第一步 下载模型文件
- pytorch_model.bin:从hf上下载Aquila模型(https://huggingface.co/BAAI/AquilaChat-7B),这里以 AquilaChat-7B 对话模型为例。
- vocab.json:在(https://github.com/FlagAI-Open/FlagAI/blob/master/examples/Aquila/Aquila-tokenizer-hf/vocab.json.llama.cpp)中下载并重命名
第二步 安装依赖项
首先,你需要安装Xcode来编译C++项目。
xcode-select --install接下来,是构建C++项目的依赖项(pkgconfig和cmake)。
brew install pkgconfig cmake在环境的配置上,假如你用的是Python 3.11,则可以创建一个虚拟环境:
/opt/homebrew/bin/python3.11 -m venv venv然后激活venv。(如果是fish以外的shell,只要去掉.fish后缀即可)
. venv/bin/activate.fish安装transformers
pip install transformers最后,安装Torch。
pip3 install --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu
第三步:编译LLaMA CPP
git clone git@github.com:ggerganov/llama.cpp.git第四步:转换模型
假设已经把AquilaChat-7B模型放在llama.cpp repo中的models/目录下; 把vocab.json 放在models/ 目录下。
# Aquila与llama不同,tokenizer基于BPE格式,为此我们在llama.cpp增加vocabtype新特性;
# BPE格式模型使用时,通过指定bpe即可,默认是llama sentencepiece格式。
python convert.py models/7B/ --vocabtype bpe 输出:
Loading model file models/7B/pytorch_model-00001-of-00002.bin
Loading model file models/7B/pytorch_model-00001-of-00002.bin
Loading model file models/7B/pytorch_model-00002-of-00002.bin
vocabtype: bpe
Loading vocab file models/7B/vocab.json
params: n_vocab:100008 n_embd:4096 n_mult:5504 n_head:32 n_layer:32
Writing vocab...
[ 1/291] Writing tensor tok_embeddings.weight | size 100008 x 4096 | type UnquantizedDataType(name='F16')
[ 2/291] Writing tensor norm.weight | size 4096 | type UnquantizedDataType(name='F32')
[ 3/291] Writing tensor output.weight | size 100008 x 4096 | type UnquantizedDataType(name='F16')
...
[291/291] Writing tensor layers.31.ffn_norm.weight | size 4096 | type UnquantizedDataType(name='F32')
Wrote models/7B/ggml-model-f16.bin下一步将是进行量化处理:
./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin 2输出:
llama.cpp: loading model from ./models/7B/ggml-model-f16.bin
llama.cpp: saving model to ./models/7B/ggml-model-q4_0.bin
[ 1/ 291] tok_embeddings.weight - 4096 x 100008, type = f16, quantizing to q4_0 .. size = 781.31 MB -> 219.74 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.111 0.117 0.111 0.097 0.077 0.056 0.039 0.025 0.021
[ 2/ 291] norm.weight - 4096, type = f32, size = 0.016 MB
[ 3/ 291] output.weight - 4096 x 100008, type = f16, quantizing to q4_0 .. size = 781.31 MB -> 219.74 MB | hist: 0.037 0.016 0.026 0.040 0.058 0.077 0.096 0.109 0.114 0.109 0.096 0.077 0.058 0.040 0.026 0.021
...
[ 291/ 291] layers.31.ffn_norm.weight - 4096, type = f32, size = 0.016 MB
llama_model_quantize_internal: model size = 13915.64 MB
llama_model_quantize_internal: quant size = 3914.50 MB
llama_model_quantize_internal: hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
main: quantize time = 32846.04 ms
main: total time = 32846.04 ms
第五步:运行模型
例一:-p ‘请给出10个要到北京旅游的理由。
./main -m ./models/7B/ggml-model-q4_0.bin \
> -t 8 \
> -n 128 \
> -p '请给出10个要到北京旅游的理由。
输出:
main: build = 955 (86c3219)
main: seed = 1691399720
llama.cpp: loading model from ./models/7B/ggml-model-q4_0.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 100008
llama_model_load_internal: n_ctx = 512
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 5504
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_head_kv = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: n_gqa = 1
llama_model_load_internal: rnorm_eps = 5.0e-06
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: freq_base = 10000.0
llama_model_load_internal: freq_scale = 1
llama_model_load_internal: ftype = 2 (mostly Q4_0)
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.08 MB
llama_model_load_internal: mem required = 3914.59 MB (+ 256.00 MB per state)
llama_new_context_with_model: kv self size = 256.00 MB
llama_new_context_with_model: compute buffer total size = 204.67 MB
system_info: n_threads = 8 / 8 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
sampling: repeat_last_n = 64, repeat_penalty = 1.100000, presence_penalty = 0.000000, frequency_penalty = 0.000000, top_k = 40, tfs_z = 1.000000, top_p = 0.950000, typical_p = 1.000000, temp = 0.800000, mirostat = 0, mirostat_lr = 0.100000, mirostat_ent = 5.000000
generate: n_ctx = 512, n_batch = 512, n_predict = 128, n_keep = 0
! 请给出10个要到北京旅游的理由。 1. 看升国旗 2.品尝烤鸭 3. 感受中国文化 4. 游览长城 5. 欣赏故宫 6. 去颐和园 7. 参观清华大学 8. 到王府井逛街 9. 逛 Beijing market 10. 前往欢乐谷游玩
例二:-p ‘简单介绍智源研究院。’
./main -m ./models/7B/ggml-model-q4_0.bin \
-t 8 \
-n 128 \
-p '简单介绍智源研究院。'
main: build = 955 (86c3219)
main: seed = 1691456827
llama.cpp: loading model from ./models/7B/ggml-model-q4_0.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 100008
llama_model_load_internal: n_ctx = 512
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 5504
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_head_kv = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: n_gqa = 1
llama_model_load_internal: rnorm_eps = 5.0e-06
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: freq_base = 10000.0
llama_model_load_internal: freq_scale = 1
llama_model_load_internal: ftype = 2 (mostly Q4_0)
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.08 MB
llama_model_load_internal: mem required = 3914.59 MB (+ 256.00 MB per state)
llama_new_context_with_model: kv self size = 256.00 MB
llama_new_context_with_model: compute buffer total size = 204.67 MB
system_info: n_threads = 8 / 8 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
sampling: repeat_last_n = 64, repeat_penalty = 1.100000, presence_penalty = 0.000000, frequency_penalty = 0.000000, top_k = 40, tfs_z = 1.000000, top_p = 0.950000, typical_p = 1.000000, temp = 0.800000, mirostat = 0, mirostat_lr = 0.100000, mirostat_ent = 5.000000
generate: n_ctx = 512, n_batch = 512, n_predict = 128, n_keep = 0
! 简单介绍智源研究院。智源研究院是一家位于中国北京的AI研究和咨询机构,致力于推动AI在各个领域的应用和发展。其研究范围涵盖自然语言处理、机器学习、人工智能等。智源研究院的主要研究方向包括语音识别、图像处理、智能问答等。同时,其还提供全面的AI解决方案和咨询服务,帮助企业和政府机构实现数字化转型和智能化管理。
资源使用情况
AquilaChat-7B 模型采用int4量化后,运行时仅使用了大约160M的内存,以及100%的CPU。

悟道·天鹰Aquila系列模型是智源研究院推出的开源大语言模型,支持免费商用许可。
使用方式一(推荐):通过 FlagAI 加载 Aquila 系列模型 https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
使用方式二:通过 FlagOpen 模型仓库单独下载权重 https://model.baai.ac.cn/
使用方式三:通过 Hugging Face 加载 Aquila 系列模型 https://huggingface.co/BAAI

相关文章






