

为了解决这个问题,面壁智能联合来自 TsinghuaNLP、耶鲁、人大、腾讯、知乎的研究人员推出 ToolLLM 工具学习框架,加入 OpenBMB 大模型工具体系“全家桶”。ToolLLM 框架包括如何获取高质量工具学习训练数据、模型训练代码和模型自动评测的全流程。作者构建了 ToolBench 数据集,该数据集囊括 16464 个真实世界 API。ToolLLM 框架的推出,有助于促进开源语言模型更好地使用各种工具,增强其复杂场景下推理能力。该创新将有助于研究人员更深入地探索 LLMs 的能力边界,也为更广泛的应用场景敞开了大门。
https://discord.gg/asjtEkAA
ToolLLM 研究背景
—
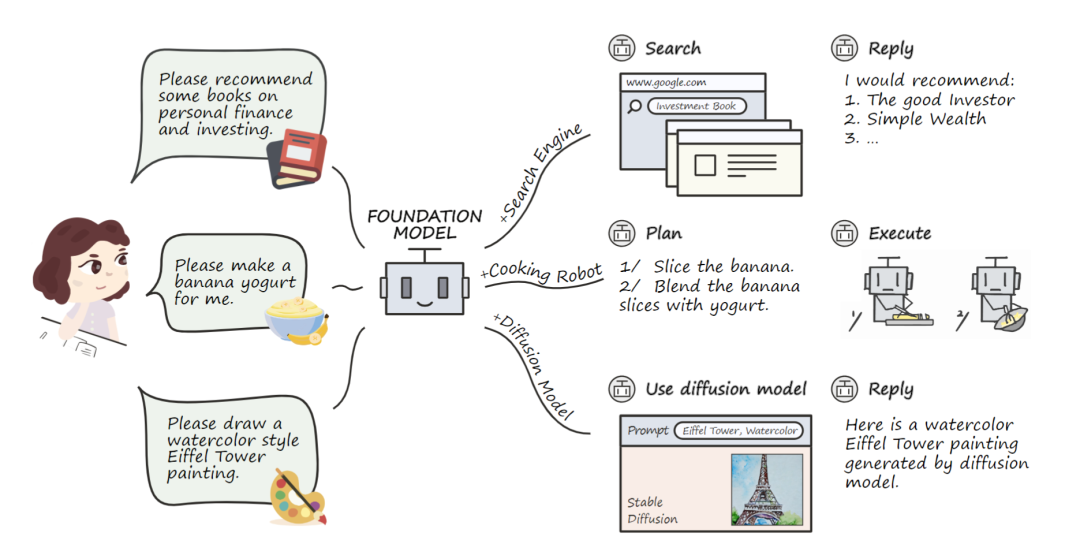
大模型工具学习范式
工具学习的目标是让LLM能给定用户指令与各种工具(API)高效交互,从而大大扩展LLM的能力边界,使其成为用户与广泛应用生态系统之间的高效桥梁。尽管已经有一些工作(例如Gorrila、APIBank等)探索了如何让LLM掌握API调用能力,这些工作仍然存在以下局限性:
1. 有限的API:很多研究没有使用真实世界的API(如RESTful API),存在API范围有限、多样性不足的问题
2. 场景受限:先前工作大多集中在单一工具的使用,而实际场景中可能需要多个工具协同工作来完成复杂任务;此外,现有研究通常假设用户提供与指令相关的API,但现实中可供选择的API可能非常多,用户难以从中高效选择
3. 模型规划和推理能力不足:现有模型推理方法如CoT、ReACT过于简单,无法充分利用LLM的潜力来处理复杂指令,因而难以处理复杂任务
ToolLLM 研究框架
—
为了激发开源LLM的工具使用能力,该研究提出了ToolLLM,一个包括数据构建、模型训练和评估过程的通用工具学习框架。作者首先收集高质量的工具学习指令微调数据集ToolBench,随后对LLaMA进行微调得到ToolLLaMA,最后通过ToolEval评估ToolLLaMA的工具使用能力。
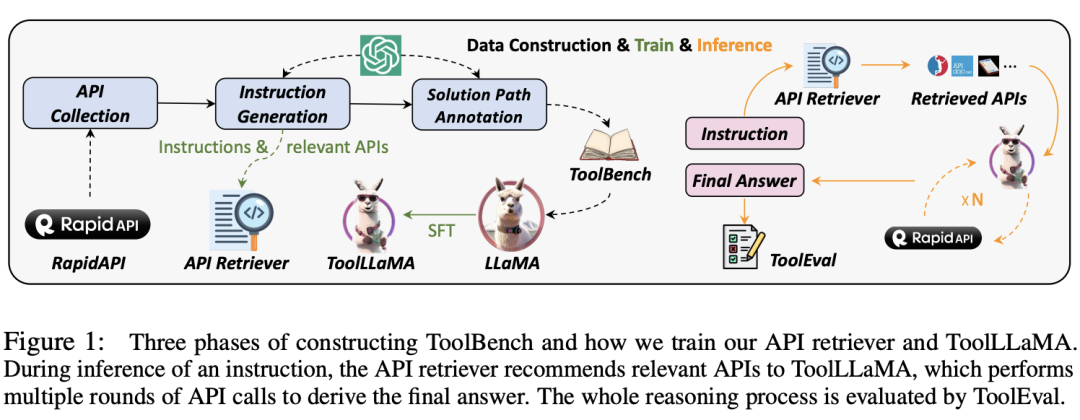
ToolLLM数据收集、模型训练、性能评测流程
ToolBench数据集
—
ToolBench 的构建完全由最新的 ChatGPT(gpt-3.5-turbo-16k)自动化完成,无需人工标注。在 ToolBench 上训练出来的模型具备极强的泛化能力,能够直接被应用到新的 API 上,无须额外训练。下表列出了 ToolBench 与之前相关工作的对比情况。ToolBench 不仅在多工具混合使用场景独一无二,且在真实 API 数量上也一骑绝尘。

ToolBench与之前相关工作的对比情况
ToolBench 的构建包括三个阶段:API 收集,指令生成和解路径标注:
01 API收集
API 收集分为 API 爬取、筛选和响应压缩三个步骤。
API 爬取:作者从 RapidAPI Hub 上收集了大量真实多样的 API。RapidAPI 是一个行业领先的 API 提供商,开发者可以通过注册一个 RapidAPI 密钥来连接各种现有 API。所有 RapidAPI 中的 API 可以分为 49 个类别,例如体育、金融和天气等;每个类别下面有若干工具,每个工具由一个或多个 API 组成
API 筛选:作者对在 RapidAPI 收集到的 10,853 个工具(53,190 个 API)基于能否正常运行和响应时间、质量等因素进行了筛选,最终保留了3,451 个高质量工具(16,464个API)
API 响应压缩:某些 API 返回的内容可能包含冗余信息导致长度太长无法输入 LLM,因此作者对返回内容进行压缩以减少其长度并同时保留关键信息。基于每个API的固定返回格式,作者使用 ChatGPT 自动分析并删除其中不重要信息,大大减少了 API 返回内容的长度
02 指令生成
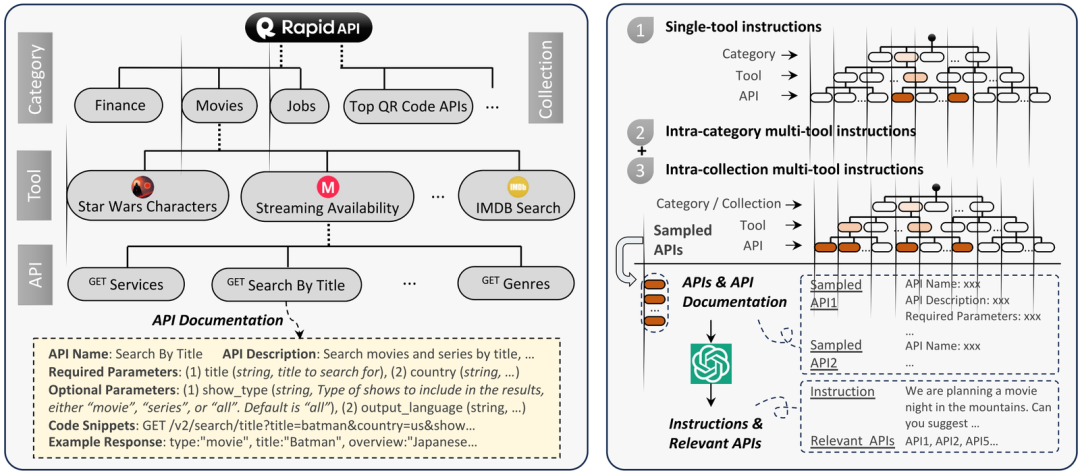
RapidAPI层次架构和工具指令生成示意图
为了兼顾生成高质量的指令和保证指令能用 API 完成,作者采用自底向上的方法进行工具指令生成,即从收集的 API 入手,反向构造涵盖各种 API 的指令。具体而言,作者首先从整个 API 集合中采样各种各样的 API 组合,接着通过 prompt engineering 让 ChatGPT 构思可能调用这些 API 的指令。
其中 prompt 包括了每个 API 的详细文档,这样 ChatGPT 能够理解不同 API 的功能和 API 之间的依赖关系,从而生成符合要求的人类指令。具体的采样方式分为单工具指令(指令涉及单工具下的多个 API)和多工具指令(指令涉及同类或跨不同类的工具的多个 API)。通过该方法,作者最终自动构造逾 20 万条合格的指令。
03 解路径标注
给定一条指令 ,作者调用 ChatGPT 来搜索(标注)一条有效的解路径(动作序列):{,…,} 。这是一个多步决策过程,由 ChatGPT 的多轮对话来完成。在每个时间步 t,模型根据先前的行为历史和 API 响应预测下一步动作 ,即:

其中 表示真实的 API 响应。每个动作包括了调用的 API 名称,传递的参数和为什么这么做的“思维过程”。为了利用 ChatGPT 新增的函数调用(function call)功能,作者将每个 API 视为一个特殊函数,并将其 API 文档放入 ChatGPT 的函数字段来让模型理解如何调用 API。此外,作者也定义了 “Give Up” 和 “Final Answer” 两种函数标识行为序列的结束。
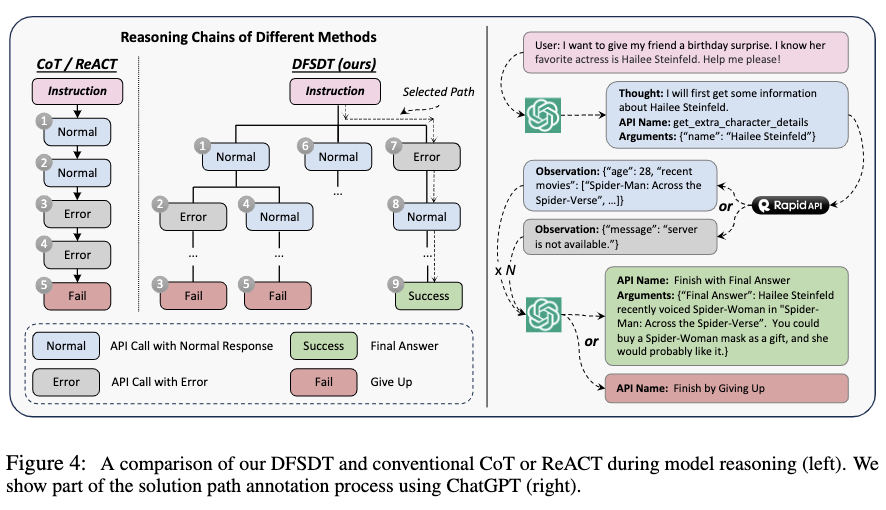
DFSDT与传统模型推理方法的对比(左图),解路径标注流程示意图(右图)
在实际应用中,作者发现传统的 CoT 或 ReACT 算法在决策过程中存在错误累加传播和搜索空间有限的问题,这导致即使是最先进的 GPT-4 在很多情况下也很难成功找到一条解路径,从而对数据标注形成了一定的障碍。
为解决这个问题,作者采用构建决策树的方式扩展搜索空间增加找到有效路径的概率。作者提出 DFSDT 算法,让模型评估不同的推理路径并沿着有希望的路径继续前进,或者放弃当前节点并扩展一个新的节点。
DFSDT于传统推理方法(ReACT)的性能比较
—

为验证 DFSDT 的效果,作者基于 ChatGPT 比较了 DFSDT 与 ReACT 的差异。此外,作者还引入了更强的 baseline (ReACT@N),它进行多次 ReACT 推理直到找到一条合理的解路径。如上图所示,DFSDT 在所有场景下的通过率(pass rate)显著更高,超越了两种 baseline。此外,DFSDT 在更复杂场景下(I2,I3)的效果提升更大,这说明扩大搜索空间更加有助于解决复杂的工具调用任务。
总而言之,DFSDT 算法显著提升了模型推理能力,增加了解路径标注的成功率。最终,作者生成了 12000+ 条指令-解路径数据对用于训练模型。
ToolEval模型评估
—
为了确保准确可靠的工具学习性能评测,作者开发了一个名为 ToolEval 的自动评估工具,它包含两个评测指标:通过率(Pass Rate)和获胜率(Win Rate)。通过率是指在有限步骤内成功完成用户指令的比例;获胜率则基于 ChatGPT 衡量两个不同解路径的好坏(即让 ChatGPT 模拟人工偏好)。
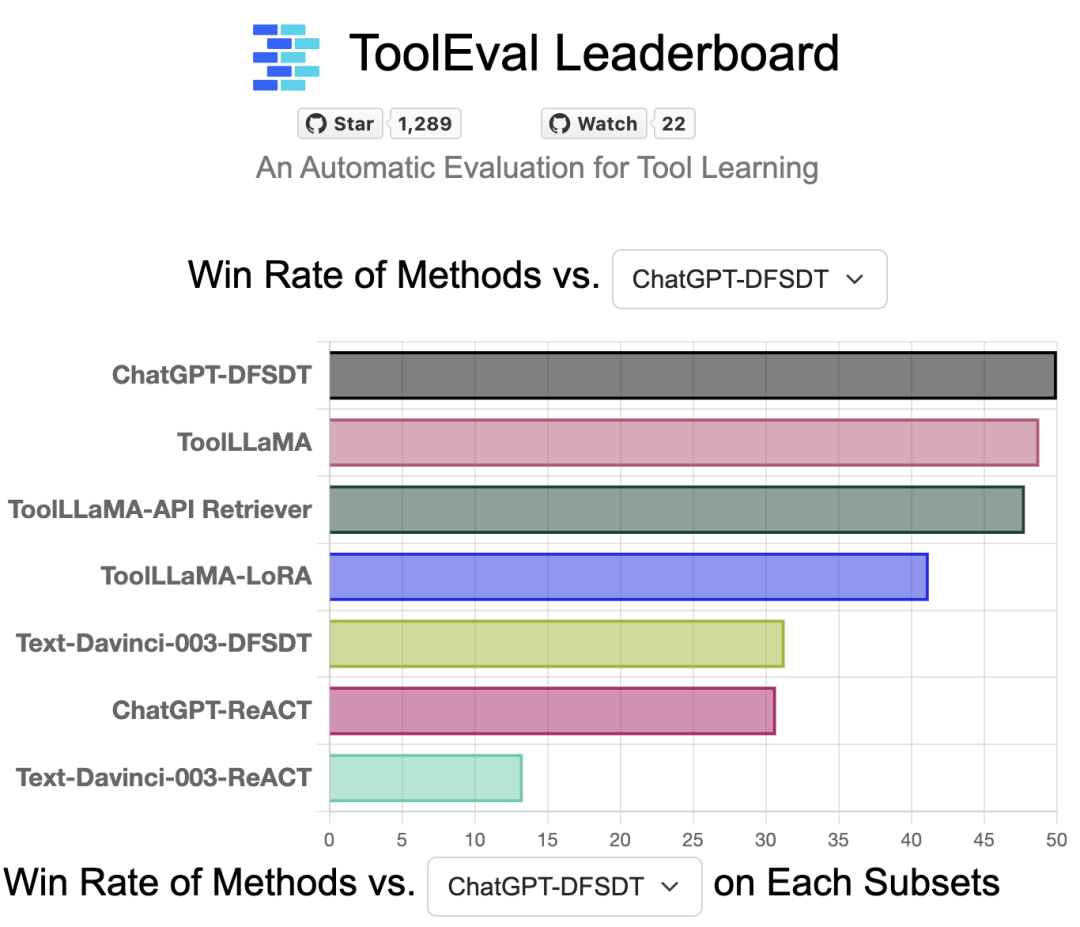
ToolEval评测工具排行榜
为了检验这种评估方式的可靠性,作者首先收集了大量人类标注结果,并且发现利用 ChatGPT 做自动评测与人类评判的一致性高达 75.8%,这意味着 ToolEval 的结评测果与人类判断高度相似。此外, ToolEval 的评测在多次重复时方差非常小(3.47%),小于人类的 3.97%,这表明,ToolEval 的评测一致性超越了人类,更加稳定可靠。
ToolLLaMA 模型训练&实验结果
—
1. 单一工具指令测试(I1):评测模型解决面向单工具的在训练中未学习过的新指令
2. 类别内多工具指令测试(I2):评测模型如何处理已经再训练中学习过的类别下的多种工具的新指令
作者选择了两个已经针对通用指令微调的 LLaMA 变体 Vicuna 和 Alpaca 以及OpenAI的ChatGPT 和 Text-Davinci-003 作为 baseline。对所有这些模型应用了更加先进的 DFSDT 推理算法,此外对 ChatGPT 应用了 ReACT。在计算 win rate 时,将每个模型与 ChatGPT-ReACT 进行比较。下面两幅图总结了 ToolLLaMA 模型和其他模型比较结果
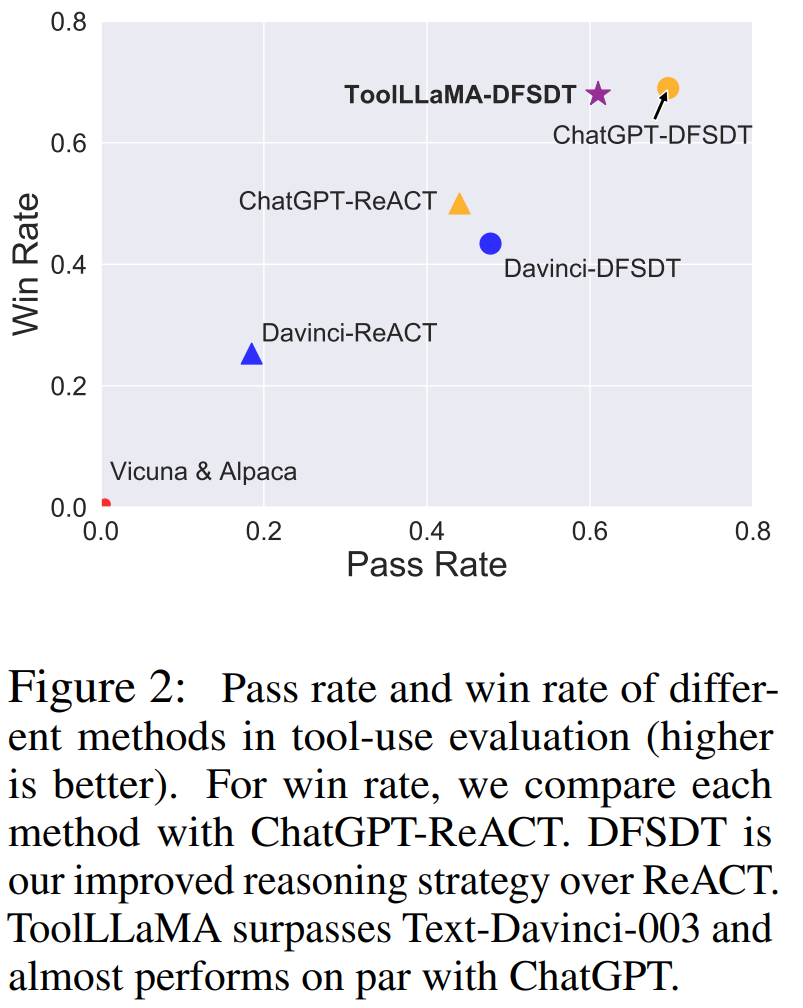
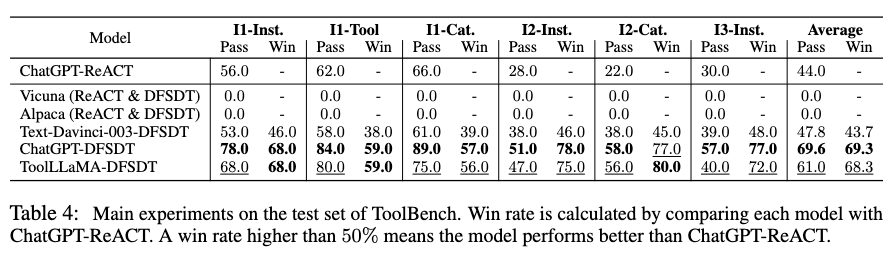
根据上图显示,ToolLLaMA 在 pass rate 和 win rate 上显著优于传统的工具使用方法 ChatGPT-ReACT,展现出优越的泛化能力,能够很容易地泛化到没有见过的新工具上,这对于用户定义新 API 并让 ToolLLaMA 高效兼容新 API 具有十分重要的意义。此外,作者发现 ToolLLaMA 性能已经十分接近 ChatGPT,并且远超 Davinci, Alpaca, Vicuna 等 baseline。
在实际情况下用户可能无法从大量的 API 中手动推荐和当前指令相关的 API,因此需要一个具备 API 自动推荐功能的模型。为解决这个问题,作者调用 ChatGPT 自动标注数据并依此训练了一个 sentence-bert 模型用作 dense retrieval。
为了测试API检索器的性能,作者比较了训练得到的 API 检索器和 BM25、Openai Ada Embedding 方法,发现该检索器效果远超 baseline,表现出极强的检索性能。此外,作者也将该检索器与 ToolLLaMA 结合,得到了更加符合真实场景的工具使用模型 pipeline。
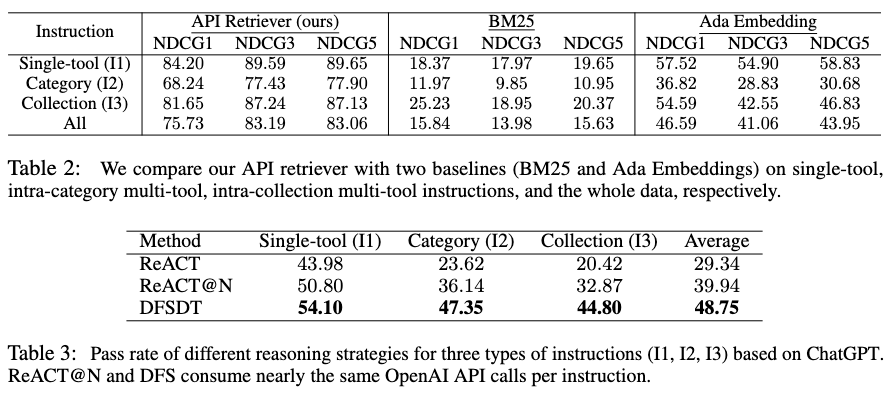
作者训练的API检索器和baseline方法的性能对比
工具学习扩展大模型能力边界
—
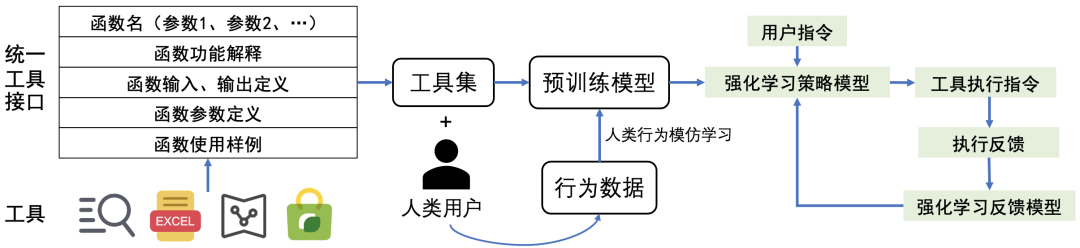

在应用方面,ChatGPT Plugins 的出现补充了 ChatGPT 最后的短板,使其可以支持连网、解决数学计算,被称为 OpenAI的“App Store” 时刻。然而直到现在,它仅支持部分OpenAI Plus用户,大多数开发者仍然无法使用。
为此,面壁智能之前也推出了工具学习引擎 BMTools,一个基于语言模型的开源可扩展工具学习平台,它将是面壁智能在大模型体系布局中的又一重要模块。研发团队将各种各样的工具(例如文生图模型、搜索引擎、股票查询等)调用流程都统一到一个框架上,使整个工具调用流程标准化、自动化。
开发者可以通过 BMTools,使用给定的模型(ChatGPT、GPT-4)调用多种多样的工具接口,实现特定功能。此外,BMTools 工具包也已集成最近爆火的 Auto-GPT 与 BabyAGI。未来,团队还将围绕大模型工具学习有更多发布,敬请大家期待!
?https://github.com/thunlp/WebCPM
➤ 加社群/提建议/有疑问 
请找 OpenBMB 万能小助手:



https://www.openbmb.org
长期开放招聘|含实习
开发岗 | 算法岗 | 产品岗
相关文章






